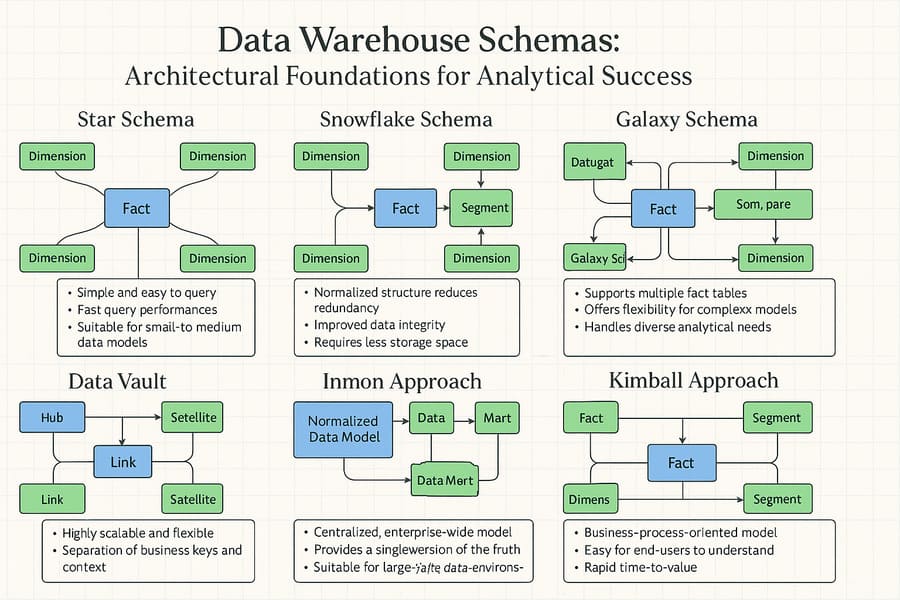
Data Warehouse Schemas: Architectural Blueprints for Analytical Success
In the realm of data engineering, few decisions have more far-reaching consequences than the selection of an appropriate data warehouse schema. This foundational architectural choice shapes not only how data is stored and related but fundamentally determines the flexibility, performance, and analytical capabilities of your entire business intelligence ecosystem. Whether you’re building a new data warehouse or evaluating your existing architecture, understanding the strengths and applications of each schema type is essential for aligning technical implementation with business objectives.
Understanding Data Warehouse Schemas
Data warehouse schemas represent the logical arrangement of tables within a data warehouse. Unlike transactional database schemas optimized for data entry and record-level operations, warehouse schemas are designed specifically for analytical processing, reporting, and complex querying across large datasets. The right schema choice depends on your specific business requirements, data complexity, available technical resources, and long-term flexibility needs.
Let’s explore the six major schema types that dominate the data warehousing landscape today:
Star Schema: Elegant Simplicity for Analytical Performance
The Star Schema stands as the most recognizable and widely implemented data warehouse model, characterized by a central fact table connected directly to multiple dimension tables in a star-like pattern.
Core Characteristics:
- Central fact table containing business metrics and foreign keys
- Denormalized dimension tables connecting directly to the fact table
- Minimized join complexity for improved query performance
- Intuitive structure that business users can easily understand
Ideal For:
This schema delivers exceptional performance for analytical workloads while maintaining a structure that business users find intuitive. It’s the go-to choice for:
- BI platforms requiring rapid dashboard performance
- Self-service analytics environments
- Data marts with clearly defined analytical objectives
- Organizations prioritizing query speed over storage efficiency
Real-World Example:
A retail sales data warehouse might implement a Star Schema with a central Sales fact table containing metrics like quantity, price, and discount, surrounded by dimensions like Customer, Product, Store, and Date.
SalesFact {
SaleID (PK)
DateKey (FK)
ProductKey (FK)
StoreKey (FK)
CustomerKey (FK)
Quantity
UnitPrice
TotalAmount
Discount
}
DimProduct {
ProductKey (PK)
ProductID
ProductName
Category
Brand
Size
Color
}
Snowflake Schema: Normalization for Complex Dimensions
The Snowflake Schema expands on the Star Schema by normalizing dimension tables into multiple related tables, reducing redundancy at the cost of more complex joins.
Core Characteristics:
- Normalized dimension tables divided into multiple related tables
- Reduced data redundancy compared to Star Schema
- Hierarchical dimensions clearly represented through table relationships
- More complex join operations required for queries
Ideal For:
This schema optimizes storage at some cost to query performance, making it appropriate for:
- Environments where storage costs are a significant concern
- Data warehouses with complex dimensional hierarchies
- Organizations with strict data quality and integrity requirements
- Scenarios where dimension tables are very large with many attributes
Real-World Example:
A product dimension in a Snowflake Schema might be normalized into multiple tables:
DimProduct {
ProductKey (PK)
ProductID
ProductName
BrandKey (FK)
CategoryKey (FK)
Size
Color
}
DimBrand {
BrandKey (PK)
BrandName
ManufacturerKey (FK)
}
DimCategory {
CategoryKey (PK)
CategoryName
DepartmentKey (FK)
}
DimDepartment {
DepartmentKey (PK)
DepartmentName
}
Galaxy Schema (Fact Constellation): Enterprise Integration
The Galaxy Schema (also known as Fact Constellation) extends beyond single-focus designs by incorporating multiple fact tables that share dimension tables, creating a constellation-like structure.
Core Characteristics:
- Multiple fact tables representing different business processes
- Shared dimension tables connecting related facts
- Enterprise-wide integration through common dimensional context
- Cross-process analytical capabilities through conformed dimensions
Ideal For:
This schema enables enterprise-wide integration and cross-process analysis, making it suitable for:
- Enterprise data warehouses supporting multiple business domains
- Organizations requiring integrated analysis across processes
- Environments needing both specialized and consolidated reporting
- Mature data warehouse implementations with stable dimensional definitions
Real-World Example:
A retail enterprise might implement a Galaxy Schema with Sales, Inventory, and Marketing facts all sharing dimensions like Product, Store, and Date:
SalesFact {
SaleID (PK)
DateKey (FK)
ProductKey (FK)
StoreKey (FK)
CustomerKey (FK)
Quantity
Amount
}
InventoryFact {
InventoryID (PK)
DateKey (FK)
ProductKey (FK)
StoreKey (FK)
QuantityOnHand
QuantityReceived
QuantitySold
}
MarketingFact {
CampaignEventID (PK)
DateKey (FK)
ProductKey (FK)
CampaignKey (FK)
Impressions
Clicks
Conversions
Cost
}
Data Vault: Adaptability for Enterprise Data Integration
The Data Vault represents a modern approach to data warehouse modeling that emphasizes long-term adaptability, auditability, and resilience to change.
Core Characteristics:
- Hub tables containing business keys and minimal metadata
- Link tables representing relationships between hubs
- Satellite tables storing descriptive attributes and historical records
- Clear separation of business keys, relationships, and attributes
Ideal For:
This schema excels in complex enterprise environments where change is constant and historical tracking is paramount:
- Organizations experiencing frequent business changes
- Enterprise data warehouses serving as the system of record
- Environments requiring complete historical auditability
- Projects needing to integrate diverse data sources over time
Real-World Example:
A customer domain in Data Vault might be modeled as:
Hub_Customer {
Customer_HK (PK)
CustomerID (Business Key)
LoadDate
RecordSource
}
Link_Customer_Account {
Link_Customer_Account_HK (PK)
Customer_HK (FK)
Account_HK (FK)
LoadDate
RecordSource
}
Sat_Customer {
Customer_HK (FK)
LoadDate (PK)
CustomerName
CustomerEmail
CustomerPhone
CustomerAddress
HashDiff
RecordSource
}
Inmon (Normalized) Approach: Enterprise-First Architecture
Bill Inmon’s approach advocates for an enterprise-wide, normalized design that serves as the foundation for departmental data marts.
Core Characteristics:
- Highly normalized (3NF) enterprise data warehouse
- Top-down approach starting with enterprise-wide modeling
- Subject-oriented, integrated, time-variant, and non-volatile
- Departmental data marts derived from the central warehouse
Ideal For:
This architecture prioritizes data integrity and enterprise-wide consistency:
- Organizations requiring a single version of truth across all departments
- Enterprises with complex data relationships requiring normalization
- Environments where data consistency takes precedence over query performance
- Projects with strong central IT governance and significant resources
Real-World Example:
An Inmon-style EDW would contain normalized entities like:
Customer {
CustomerID (PK)
CustomerName
CustomerType_ID (FK)
DateCreated
Status_ID (FK)
}
Account {
AccountID (PK)
CustomerID (FK)
AccountType_ID (FK)
OpenDate
CloseDate
Balance
Status_ID (FK)
}
Transaction {
TransactionID (PK)
AccountID (FK)
TransactionType_ID (FK)
TransactionDate
Amount
}
Kimball (Dimensional) Approach: Business-Driven Design
Ralph Kimball’s dimensional modeling approach takes a bottom-up perspective, focusing on business processes and dimensional consistency across the enterprise.
Core Characteristics:
- Dimensional model using star or snowflake schemas
- Bottom-up approach starting with specific business processes
- Conformed dimensions shared across multiple fact tables
- Bus architecture enabling incremental implementation
Ideal For:
This methodology prioritizes business usability and analytical performance:
- Organizations prioritizing business user accessibility
- Projects requiring incremental delivery of value
- Environments where query performance is a primary concern
- Business intelligence and analytics-focused implementations
Real-World Example:
A Kimball implementation would focus on dimensional models for specific business processes:
Sales_Fact {
SaleID (PK)
DateKey (FK)
ProductKey (FK)
StoreKey (FK)
CustomerKey (FK)
Quantity
Amount
}
Dim_Date {
DateKey (PK)
Date
Day
Month
Quarter
Year
IsHoliday
}
Dim_Product {
ProductKey (PK)
ProductID
ProductName
Category
Subcategory
Brand
Size
Color
}
Choosing the Right Schema: Key Considerations
The selection of an appropriate data warehouse schema should be driven by several key factors:
1. Business Requirements
- What types of analyses and reports do business users need?
- How important is query performance versus storage efficiency?
- What level of historical tracking is required?
2. Data Complexity
- How many business processes need to be modeled?
- How complex are the relationships between business entities?
- How frequently do business definitions and structures change?
3. Technical Constraints
- What is the available technical expertise for implementation and maintenance?
- Are there specific storage or performance limitations to consider?
- What ETL capabilities are available for maintaining the schema?
4. Evolutionary Path
- Will the data warehouse grow significantly over time?
- How likely are major structural changes to business entities?
- Is there a need to incorporate new data sources in the future?
Hybrid Approaches: Pragmatic Schema Selection
In practice, many successful data warehouses implement hybrid approaches, combining elements from different schemas to address specific requirements:
Data Vault Core with Dimensional Presentation
- Use Data Vault for the integration layer
- Publish star schema data marts for analytical access
- Gain adaptability in the core with performance at the edge
Inmon EDW with Kimball Data Marts
- Implement a normalized EDW for enterprise integration
- Create dimensional data marts for business-specific analytics
- Maintain integrity at the core with usability at the access layer
Mixed Schema Types for Different Domains
- Apply star schemas for stable, performance-critical domains
- Implement Data Vault for rapidly evolving business areas
- Use Snowflake designs for complex dimensional hierarchies
Modern Trends in Data Warehouse Schema Design
Several emerging trends are influencing schema design in contemporary data warehouses:
Cloud-Native Implementations
- Separation of storage and compute resources
- Pay-per-query economic models
- Elastic scaling influencing schema decisions
Real-Time Data Integration
- Streaming data incorporation
- Micro-batch processing
- Near-real-time reporting requirements
Data Lakehouse Architectures
- Schema-on-read approaches
- Multi-modal data persistence
- Hybrid batch and streaming processing
Metadata-Driven Approaches
- Automated schema generation and evolution
- Dynamic data transformation
- Self-describing data formats
Conclusion: Aligning Schema with Strategic Objectives
The choice of data warehouse schema is ultimately a strategic decision that should align with both current business requirements and long-term organizational objectives. The most successful implementations typically start with a clear understanding of analytical needs, data characteristics, and technical constraints before selecting an appropriate schema or hybrid approach.
By understanding the strengths and limitations of each schema type, data engineers and architects can make informed decisions that balance immediate analytical needs with long-term flexibility and maintainability. Whether you choose the simplicity of a Star Schema, the adaptability of Data Vault, or the enterprise integration of a Galaxy Schema, the key is ensuring that your architectural choice supports the ultimate purpose of any data warehouse: transforming raw data into actionable business insights.
Keywords: data warehouse schema, star schema, snowflake schema, galaxy schema, fact constellation, data vault, Inmon approach, Kimball approach, dimensional modeling, business intelligence, data architecture, data engineering, data mart, enterprise data warehouse, ETL processing
Hashtags: #DataWarehouse #SchemaDesign #StarSchema #SnowflakeSchema #GalaxySchema #DataVault #InmonVsKimball #DimensionalModeling #DataArchitecture #BusinessIntelligence #FactTable #DimensionTable #DataEngineering #ETLProcessing #DataStrategy



