Data Engineering: The Foundation of Modern Data-Driven Organizations
In today’s digital economy, data has become the most valuable asset for organizations across industries. However, raw data alone provides little value—it must be collected, processed, transformed, and made accessible to drive meaningful business insights. This is where Data Engineering emerges as the critical discipline that transforms chaotic data streams into reliable, scalable, and actionable information systems.
Data Engineering is the practice of designing, building, and maintaining the infrastructure and systems that enable organizations to collect, store, process, and analyze data at scale. Far more than just moving data from point A to point B, modern data engineering encompasses the entire data lifecycle, ensuring data quality, reliability, and accessibility for downstream consumers including data scientists, analysts, and business stakeholders.
The Evolution of Data Engineering
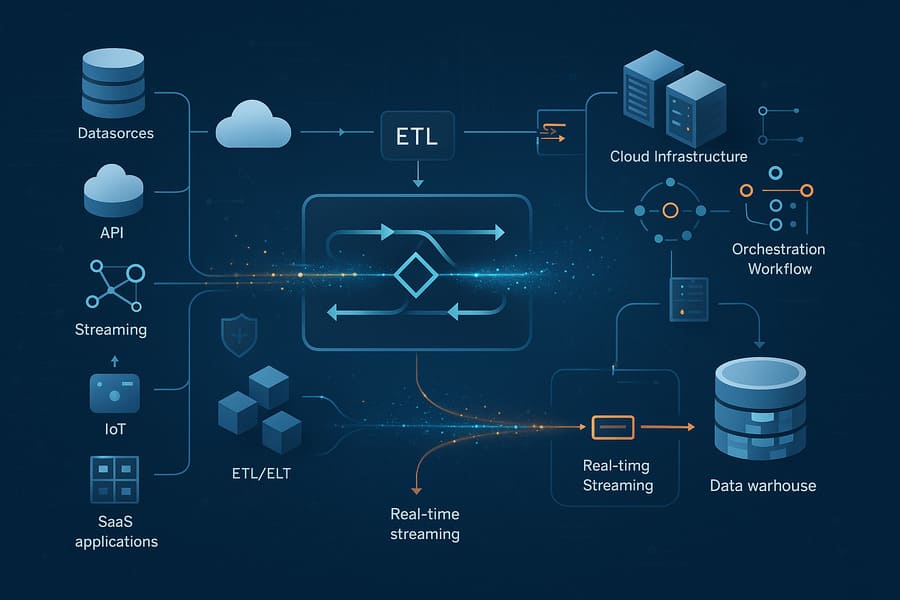
The data engineering landscape has undergone dramatic transformation over the past decade. Traditional ETL (Extract, Transform, Load) processes that once required massive upfront investments in hardware and lengthy development cycles have evolved into cloud-native, real-time data pipelines that can scale elastically with business demands.
From Batch to Real-Time: Where organizations once accepted daily or weekly data updates, modern businesses demand real-time insights. Data engineers now architect streaming pipelines that process millions of events per second, enabling instant decision-making and responsive customer experiences.
From On-Premises to Cloud-Native: The shift to cloud platforms like AWS, Azure, and Google Cloud has democratized access to enterprise-grade data infrastructure. Data engineers now leverage managed services, serverless architectures, and auto-scaling capabilities to build robust systems without the overhead of infrastructure management.
From ETL to ELT: The emergence of powerful cloud data warehouses like Snowflake, BigQuery, and Databricks has reversed the traditional transformation paradigm. Modern data engineers often load raw data first, then transform it within the warehouse, enabling greater flexibility and faster time-to-insight.
Core Responsibilities of Data Engineers
Data engineers serve as the architects of an organization’s data infrastructure, with responsibilities spanning multiple technical domains:
Data Pipeline Architecture: Designing and implementing robust, scalable pipelines that can handle varying data volumes, velocities, and varieties. This includes batch processing systems for large-scale analytics and streaming architectures for real-time applications.
Data Integration: Connecting disparate data sources—from traditional databases and APIs to modern SaaS applications and IoT devices—into unified, accessible systems. Data engineers must navigate various data formats, protocols, and quality issues while maintaining data lineage and governance.
Infrastructure Management: Building and maintaining the underlying systems that power data operations. This includes managing compute resources, storage systems, networking, security, and monitoring across cloud and hybrid environments.
Data Quality and Governance: Implementing automated data validation, quality checks, and governance frameworks that ensure data accuracy, consistency, and compliance with regulatory requirements like GDPR and CCPA.
Performance Optimization: Continuously monitoring and tuning data systems for optimal performance, cost-efficiency, and reliability. This includes query optimization, resource allocation, and implementing caching strategies.
Collaboration and Enablement: Working closely with data scientists, analysts, and business teams to understand requirements and deliver data solutions that drive business value. Data engineers often serve as technical consultants, helping teams navigate complex data challenges.
The Modern Data Engineering Stack
Today’s data engineering ecosystem is built on a foundation of specialized tools and platforms, each designed to address specific aspects of the data lifecycle:
Data Ingestion and Integration: Tools like Apache Kafka, AWS Kinesis, and Fivetran enable real-time data streaming and automated data integration from hundreds of sources.
Data Processing and Transformation: Frameworks such as Apache Spark, dbt, and Apache Beam provide the computational power to process massive datasets and implement complex business logic.
Data Storage and Warehousing: Modern data warehouses like Snowflake, Amazon Redshift, and Google BigQuery offer virtually unlimited scale with SQL-based interfaces familiar to analysts.
Workflow Orchestration: Platforms like Apache Airflow, Prefect, and Dagster coordinate complex data workflows, manage dependencies, and handle failure recovery automatically.
Data Observability: Tools such as Monte Carlo, Datafold, and Great Expectations provide monitoring, alerting, and data quality validation across the entire data pipeline.
Key Challenges in Modern Data Engineering
Despite technological advances, data engineers face several persistent challenges that require both technical expertise and strategic thinking:
Data Quality at Scale: As data volumes grow exponentially, maintaining data quality becomes increasingly complex. Data engineers must implement automated validation, anomaly detection, and quality monitoring systems that can operate at scale without human intervention.
Real-Time Processing Requirements: Business demands for real-time insights require data engineers to architect systems that can process streaming data with minimal latency while maintaining accuracy and consistency.
Data Security and Privacy: With increasing regulatory scrutiny and cyber threats, data engineers must implement comprehensive security measures including encryption, access controls, data masking, and audit trails throughout the data pipeline.
Cost Optimization: Cloud computing offers scalability but can lead to unexpected costs. Data engineers must optimize resource utilization, implement auto-scaling, and choose the right service tiers to balance performance with cost-effectiveness.
Technical Complexity: The modern data stack involves dozens of specialized tools, each requiring deep expertise. Data engineers must stay current with rapidly evolving technologies while maintaining stable, production-grade systems.
The Business Impact of Data Engineering
Effective data engineering directly translates into tangible business outcomes across multiple dimensions:
Accelerated Decision-Making: Well-architected data pipelines reduce the time from data generation to actionable insights from weeks to minutes, enabling organizations to respond quickly to market changes and opportunities.
Improved Data Quality: Robust data engineering practices ensure that business decisions are based on accurate, consistent, and reliable information, reducing the risk of costly mistakes.
Enhanced Customer Experience: Real-time data processing enables personalized customer experiences, dynamic pricing, fraud detection, and proactive customer service that drive satisfaction and loyalty.
Operational Efficiency: Automated data pipelines eliminate manual processes, reduce errors, and free up human resources for higher-value activities like analysis and strategic planning.
Competitive Advantage: Organizations with superior data infrastructure can innovate faster, identify market opportunities earlier, and adapt more quickly to changing business conditions.
Essential Skills for Data Engineers
Success in data engineering requires a diverse skill set spanning multiple technical and business domains:
Programming Proficiency: Strong command of languages like Python, SQL, Scala, and Java, with the ability to write clean, efficient, and maintainable code for data processing applications.
Distributed Systems Knowledge: Understanding of distributed computing concepts, including data partitioning, fault tolerance, consistency models, and performance optimization across multiple nodes.
Cloud Platform Expertise: Hands-on experience with major cloud providers (AWS, Azure, GCP) and their data services, including understanding of pricing models, service limitations, and best practices.
Data Modeling and Architecture: Ability to design efficient data models, understand database internals, and architect systems that balance performance, scalability, and maintainability.
DevOps and Infrastructure: Knowledge of containerization (Docker, Kubernetes), infrastructure as code (Terraform, CloudFormation), and CI/CD practices for reliable data pipeline deployment.
Business Acumen: Understanding of business requirements, ability to translate technical concepts for non-technical stakeholders, and awareness of how data engineering decisions impact business outcomes.
The Future of Data Engineering
The data engineering field continues to evolve rapidly, driven by emerging technologies and changing business requirements:
AI-Driven Automation: Machine learning is increasingly being applied to data engineering tasks, from automated data quality monitoring to intelligent pipeline optimization and predictive scaling.
Serverless and Event-Driven Architectures: The trend toward serverless computing is enabling more cost-effective, scalable data processing with reduced operational overhead.
Data Mesh and Decentralized Architectures: Organizations are moving away from centralized data warehouses toward distributed, domain-specific data ownership models that improve agility and reduce bottlenecks.
Enhanced Privacy and Security: New technologies like differential privacy, homomorphic encryption, and zero-trust architectures are becoming essential components of data infrastructure.
Real-Time Everything: The demand for real-time processing is expanding beyond traditional use cases to include machine learning inference, complex event processing, and automated decision-making.
Getting Started with Data Engineering
For organizations looking to build or enhance their data engineering capabilities, success requires a strategic approach that balances immediate needs with long-term scalability:
Start with Clear Objectives: Define specific business outcomes you want to achieve through better data infrastructure, whether that’s faster reporting, improved customer experiences, or new analytical capabilities.
Assess Current State: Conduct a thorough audit of existing data sources, systems, and processes to identify gaps, inefficiencies, and improvement opportunities.
Choose the Right Tools: Select technologies that align with your organization’s scale, technical expertise, and long-term strategy rather than chasing the latest trends.
Invest in Skills: Whether hiring experienced data engineers or upskilling existing team members, building internal expertise is crucial for long-term success.
Implement Incrementally: Start with high-impact, lower-risk projects to demonstrate value before undertaking major infrastructure overhauls.
Key Takeaways
Data Engineering has evolved from a supporting function to a critical business capability that enables organizations to compete effectively in the digital economy. Success requires combining technical expertise with business understanding, leveraging modern cloud-native tools while maintaining focus on reliability, scalability, and cost-effectiveness.
The field continues to evolve rapidly, with new technologies and approaches emerging regularly. However, the fundamental principles remain constant: build reliable systems, ensure data quality, optimize for performance and cost, and always keep the end user’s needs in focus.
Whether you’re just beginning your data engineering journey or looking to modernize existing infrastructure, remember that effective data engineering is not just about technology—it’s about enabling your organization to make better decisions faster, ultimately driving business growth and innovation.
As you explore the comprehensive ecosystem of data engineering tools and technologies outlined below, consider how each component fits into your overall data strategy and how they work together to create a cohesive, powerful data infrastructure that serves your organization’s unique needs.



