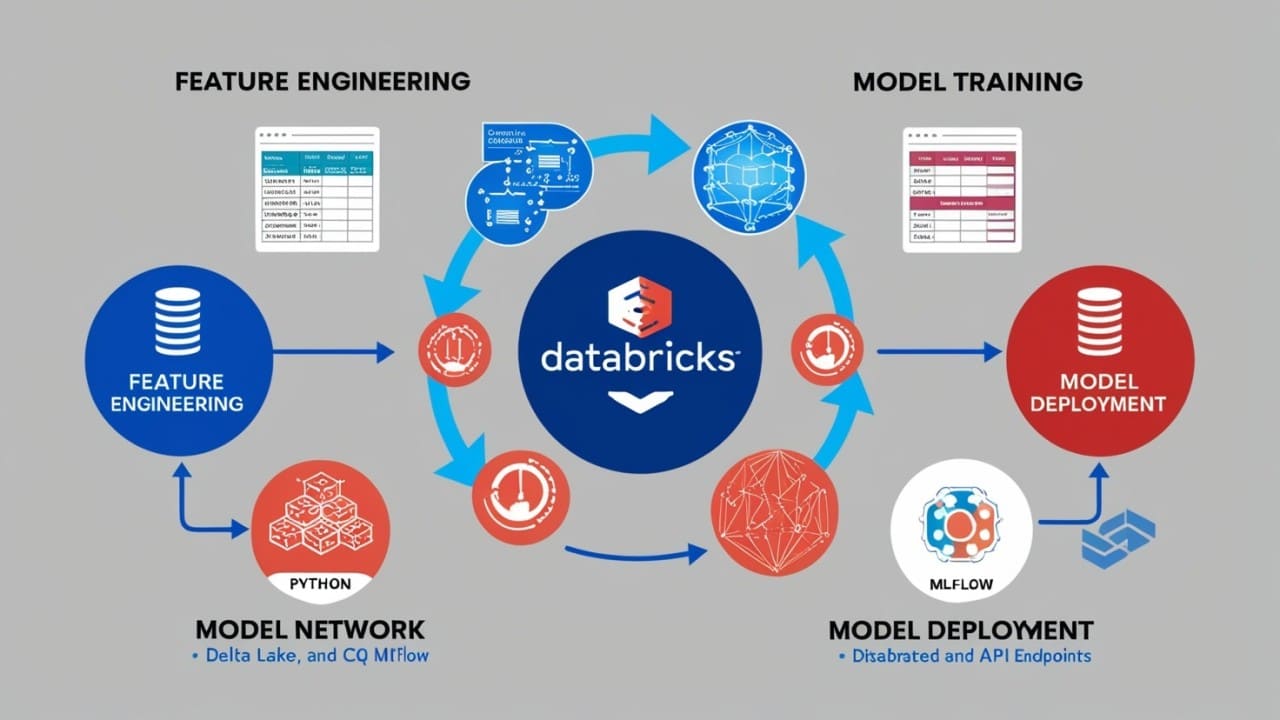
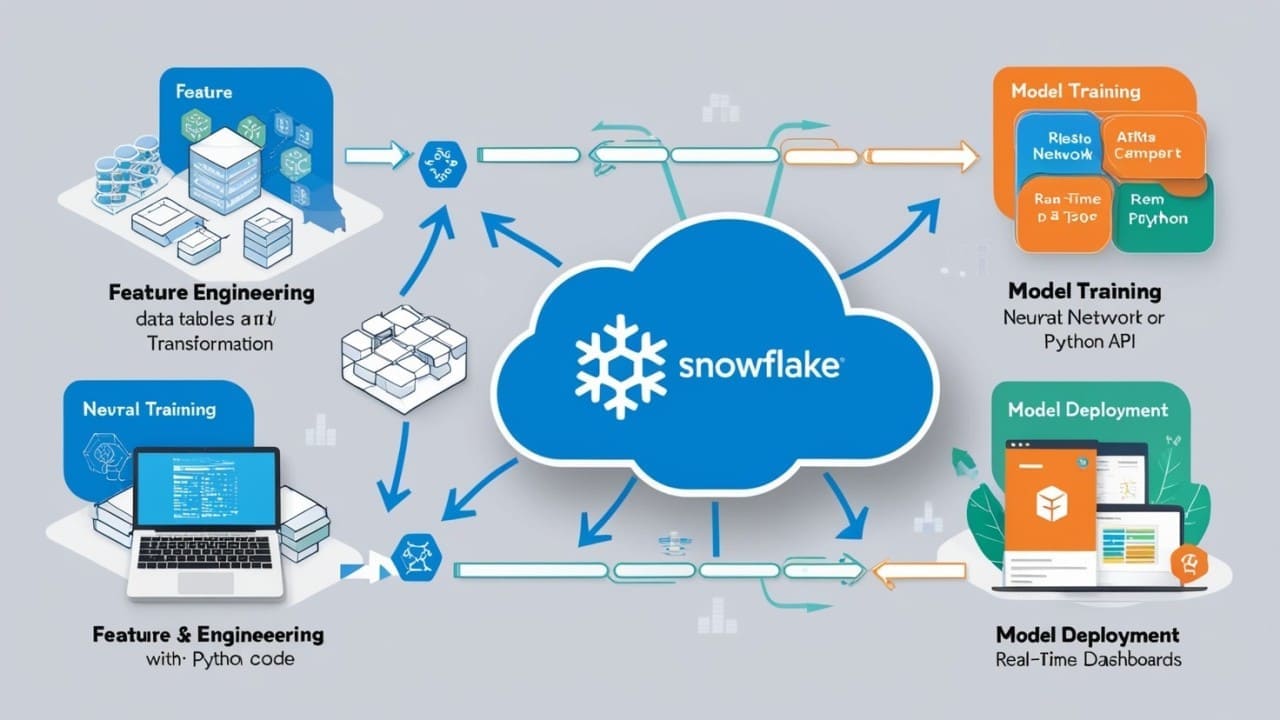
AIVector Databases for Data Engineers: Building Semantic Search at Scale Without ML ExpertiseUstas|Apr 12, 2025|1 min read