QuestDB Query Engine Internals: Vectorized Execution, JIT, and Page Frames
Why this matters (hook)
You optimized indexes. You pruned partitions. Still, your time-series query drifts into seconds. QuestDB’s speed doesn’t come from one magic index—it comes from how the engine moves data through the CPU: page frames, vectorized operators, and a JIT that compiles hot filters to native AVX2. If you’re a mid-level data engineer, mastering these internals turns “hmm, slow” into “yep, sub-second.”
Mental model: how QuestDB runs a query
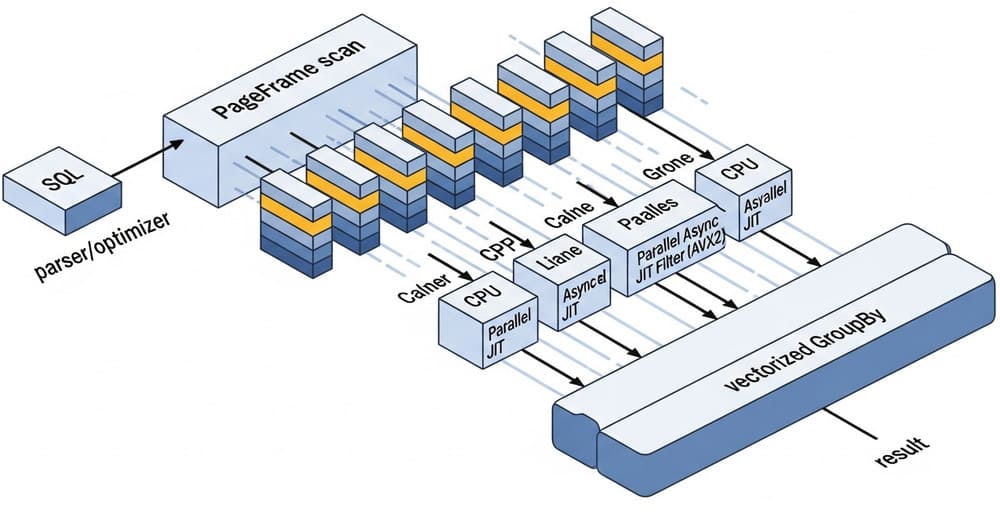
At a high level, QuestDB’s engine parses SQL, plans operators, and runs them in a tight pipeline over table page frames—columnar chunks optimized for CPU caches. The pipeline mixes vectorized execution and JIT-compiled filters, with multi-threading where it helps. Query plans and data pages are cached to avoid rework. (QuestDB)
Key pieces to remember:
- Columnar, memory-mapped reads. Fixed-size columns are accessed by translating a record id into a file offset (bit-shift), then into a lazily mapped memory page. It’s cache-friendly and fast. (QuestDB)
- PageFrame operator. In EXPLAIN,
PageFramemeans a full/partial scan over frames, with child nodes that iterate rows and partitions. It’s the workhorse for large scans. (QuestDB) - Vectorization + JIT. WHERE-clause filters can be JIT-compiled to native code that uses SIMD (AVX2) and run in parallel; other nodes (e.g., some GROUP BY) can also be vectorized. (QuestDB)
- Multi-threading where it pays. Some stages (e.g.,
SAMPLE BY, many GROUP BYs) run multi-threaded; index-based scans may remain single-threaded. (QuestDB)
Page frames, vectorization, and JIT—what each actually does
Page frames (how data is fed to the CPU)
- What: Column chunks (“frames”) that flow through operators like filters and aggregations.
- Why: Batch processing reduces overhead and improves cache locality—EXPLAIN shows
PageFramewith row and frame scans. (QuestDB) - Proof in docs/code: The engine “process[es] data in table page frames” and has concrete factories like
PageFrameRecordCursorFactory. (QuestDB)
Vectorized execution (SIMD)
- What: Apply the same operation to many values at once using CPU vector instructions.
- Where: Filters, aggregations, and other operators when the data types align. EXPLAIN may show
vectorized: trueon some nodes. (QuestDB) - Why it’s fast: Maximizes per-cycle work and cache use; central to QuestDB’s engine design. (QuestDB)
JIT compilation (when WHERE turns into native code)
- What: The engine compiles certain WHERE filters to native machine code using AVX2. Enabled by default; configurable via
cairo.sql.jit.mode. (QuestDB) - When it triggers: Queries (or subqueries) that scan a table/partitions and have arithmetic filters on fixed-size columns (e.g., INT, DOUBLE, TIMESTAMP, SYMBOL). (QuestDB)
- Limits to know: x86-64 only; vectorized filter needs AVX2; many SQL functions/pseudo-functions in filters disable JIT. (QuestDB)
Reading the plan: a tiny tour with EXPLAIN
EXPLAIN SELECT *
FROM trades
WHERE amount > 100.0;
Typical output (simplified):
Async JIT Filter workers: 32
filter: 100.0<amount
PageFrame
Row forward scan
Frame forward scan on: trades
What to take away:
Async JIT Filter→ JIT compiled and parallelized WHERE.PageFrame→ full/partial scan over frames (columnar batches).- Workers count → upper bound; actual threads may be fewer at runtime. (QuestDB)
For GROUP BY, you may see vectorized: true, meaning SIMD paths are used. (QuestDB)
How storage feeds the engine
QuestDB writes via a row-based WAL for high ingest, then stores in columnar native format; older partitions can tier to Parquet while remaining queryable. The columnar layout is exactly what lets page frames + SIMD shine. (QuestDB)
Quick comparison: JIT vs vectorized vs row-at-a-time
| Aspect | Row-at-a-time | Vectorized execution | JIT-compiled filter |
|---|---|---|---|
| CPU use | Poor cache, branchy | Good cache, batched | Best for supported WHERE predicates |
| Parallelism | Limited | Often | Often (Async JIT Filter) |
| Data types | Any | Best with fixed-size columns | Only fixed-size columns in filters |
| Where seen | Fallback paths | GroupBy/SampleBy/filters | WHERE filters on scans |
| Common blockers | N/A | Misaligned schemas | Functions in filter, non-fixed types |
Sources: engine overview, EXPLAIN semantics, JIT docs. (QuestDB)
Real example: build a JIT-friendly query
Schema (designated timestamp and symbols for tags):
CREATE TABLE trades (
symbol SYMBOL CAPACITY 256 CACHE,
price DOUBLE,
amount DOUBLE,
ts TIMESTAMP
) TIMESTAMP(ts) PARTITION BY DAY;
A JIT-eligible filter on fixed-size columns:
EXPLAIN
SELECT symbol, count()
FROM trades
WHERE ts IN today()
AND amount > 100.0
GROUP BY symbol;
What you want to see:
Async JIT Filterabove aPageFramescan.- For the aggregation, a
GroupBy … vectorized: truewhen possible. (QuestDB)
If you don’t see JIT: remove functions from the WHERE, avoid between on non-designated timestamps, or casting that changes types mid-filter. (QuestDB)
Tuning checklist (practical, not dogma)
- Make filters JIT-friendly.
- Keep WHERE arithmetic simple on fixed-size types; avoid
abs(),round(),now(),in()on symbols in the filter. (QuestDB)
- Keep WHERE arithmetic simple on fixed-size types; avoid
- Prefer scans over random access when feasible.
- Many queries run fastest as frame scans with SIMD filters and parallel workers; some index paths remain single-threaded. Validate with
EXPLAIN. (QuestDB)
- Many queries run fastest as frame scans with SIMD filters and parallel workers; some index paths remain single-threaded. Validate with
- Partition and types matter.
- Use a designated timestamp and partitions; use
SYMBOLinstead of free-text for high-cardinality tags to keep columns fixed-size where you can benefit from vectorization and JIT. (Design/type choices power vectorized paths.) (QuestDB)
- Use a designated timestamp and partitions; use
- Configure JIT consciously.
- Enabled by default; temporarily toggle with
cairo.sql.jit.modefor experiments. Check logs for JIT usage or read plans withEXPLAIN. (QuestDB)
- Enabled by default; temporarily toggle with
- Mind client behavior.
- QuestDB doesn’t support server-side (scrollable) cursors; use forward-only iteration and size your fetches in the client. Don’t expect Postgres
DECLARE CURSORsemantics. (QuestDB)
- QuestDB doesn’t support server-side (scrollable) cursors; use forward-only iteration and size your fetches in the client. Don’t expect Postgres
- Cache is king.
- Hot data stays in memory-mapped pages; historical tiers (including Parquet) remain queryable but colder. Expect differences in latency across tiers. (QuestDB)
Common pitfalls (and how to fix them)
- “My WHERE uses a function; JIT didn’t trigger.”
Refactor the predicate so arithmetic on fixed-size columns stands alone; pre-compute literals outside the filter. (QuestDB) - “Workers show 64 in EXPLAIN but runtime is slow.”
Worker count is an upper bound; skewed groups or IO can cap real throughput. Check that the node is vectorized/JIT and that partitions fit memory. (QuestDB) - “Index made things slower.”
Some index scans are single-threaded and defeat vectorized filters. For broad time ranges, frame scans + JIT win. Validate withEXPLAIN. (QuestDB) - “Reading via Postgres driver is memory-heavy.”
Use forward-only iteration; don’t rely on server-side cursor semantics not supported by QuestDB. (QuestDB)
Internal link ideas (official)
- Query engine overview – components, page frames, SIMD, multi-threading. (QuestDB)
- JIT compiler concept – eligibility, limits, configuration. (QuestDB)
- EXPLAIN – what plan nodes mean (
PageFrame, workers, vectorized flags). (QuestDB) - Storage engine (three-tier) – WAL → native columnar → Parquet tiers. (QuestDB)
- Storage model – memory mapping, fixed-size column reads. (QuestDB)
- Configuration – where to set server options (e.g., JIT mode). (QuestDB)
Summary & call to action
QuestDB’s speed is architectural: feed the CPU page frames, do work in vectors, and—when filters qualify—compile them to AVX2. Read the plan, align schemas and predicates with vectorized/JIT paths, and don’t let client assumptions (like server-side cursors) kneecap throughput. Next step: take a workload, run EXPLAIN, and fix one predicate at a time.








Leave a Reply