Multi-Agent Orchestration: Building Collaborative AI Agent Systems for Enterprise Data Workflows
Introduction
Enterprise data workflows are becoming too complex for single-agent systems to handle effectively. Organizations process terabytes of data daily across distributed systems, requiring decisions about schema changes, data quality issues, pipeline failures, and resource allocation. A single AI agent can't maintain the specialized knowledge needed for each of these domains.
Multi-agent orchestration solves this by deploying specialized AI agents that collaborate on complex tasks. Meta runs agents that help engineers query their data warehouse using natural language. Microsoft's Agent Framework enables teams to build coordinated agent systems on Azure. These aren't experimental projects. They're production systems handling real workloads.
This article explains how to architect multi-agent systems for enterprise data workflows. You'll learn coordination patterns, communication protocols, and how to maintain observability when multiple agents work together. We'll cover what works in production and what doesn't.
Why Single-Agent Systems Fall Short
Traditional orchestration tools like Airflow and Prefect execute predefined workflows. They're deterministic. You write a DAG, they run it. Adding intelligence meant building custom logic into your pipeline code.
Single AI agents tried to solve this by embedding LLMs into orchestration layers. The agent could interpret natural language requests, adjust schedules based on context, and respond to pipeline failures. But they hit limits quickly.
The specialization problem: A data quality agent needs different knowledge than a cost optimization agent. Training one agent to handle both reduces performance on each task. The agent becomes a generalist that doesn't excel at anything.
The context problem: Enterprise workflows involve multiple systems. Your data warehouse, streaming platforms, object storage, metadata catalogs, and monitoring tools. One agent can't maintain connections to all of these while processing requests efficiently.
The scaling problem: As workflow complexity grows, single agents become bottlenecks. They queue requests, increasing latency. Adding more instances doesn't help because they don't coordinate with each other.
Multi-agent systems address these issues by distributing specialized capabilities across multiple agents that communicate and coordinate.
Core Architecture Patterns
Hierarchical Coordination
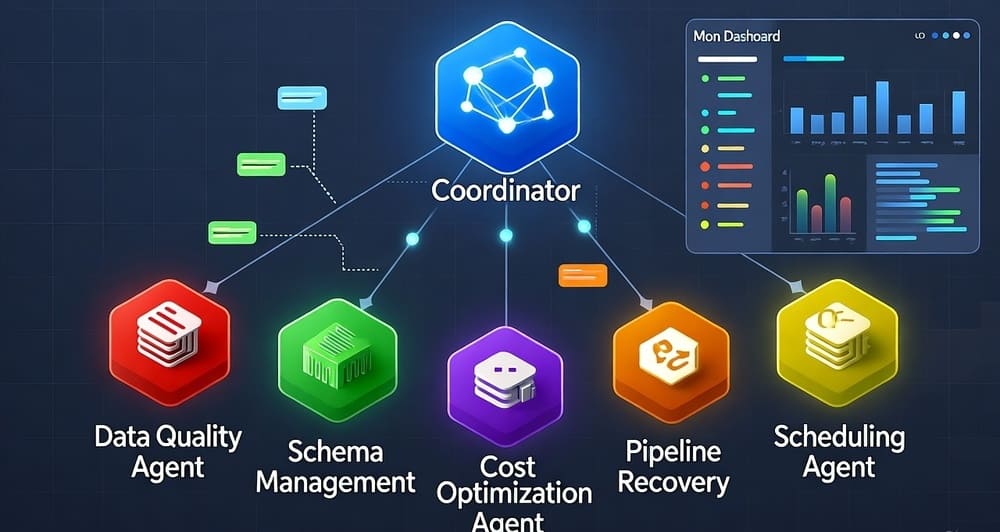
The most common pattern in production uses a coordinator agent that delegates tasks to specialized workers. Think of it as a tech lead distributing work to team members.
The coordinator receives requests, determines which specialized agents should handle them, and manages the overall workflow state. Worker agents focus on their domains without worrying about the bigger picture.
Meta's data warehouse agents follow this pattern. When an engineer asks about query performance, the coordinator routes the request to specialized agents for query optimization, schema analysis, and resource usage. Each agent returns findings. The coordinator synthesizes them into a coherent response.
Implementation considerations: Your coordinator needs a clear decision tree for routing requests. Use structured outputs from your LLM to get reliable routing decisions. Don't rely on parsing free-form text responses.
The coordinator also handles failure scenarios. If a worker agent times out or returns an error, the coordinator decides whether to retry, route to a backup agent, or fail gracefully with a partial response.
Peer-to-Peer Collaboration
Some workflows benefit from agents that communicate directly without a central coordinator. This works when agents need to negotiate or reach consensus.
Consider a data pipeline that ingests from multiple sources. One agent monitors source freshness, another validates schema compatibility, and a third manages backpressure. They need to coordinate in real time as conditions change.
In peer-to-peer systems, agents maintain awareness of other agents' states. They use message passing to share updates and make collective decisions. This reduces latency compared to routing everything through a coordinator.
When to use this pattern: Workflows where agents need to react to each other's actions quickly. Real-time data processing pipelines, dynamic resource allocation, and multi-stage validation processes.
Trade-offs: Peer-to-peer systems are harder to debug. Understanding why agents made specific decisions requires tracing message flows across multiple agents. Your observability stack needs to handle this.
Hub-and-Spoke with Shared State
This pattern combines elements of both hierarchical and peer-to-peer approaches. A central state manager maintains shared context while agents communicate directly for time-sensitive coordination.
Dagster and Prefect are adding this capability for AI-enhanced scheduling. Agents access shared state about pipeline history, resource availability, and business constraints. They coordinate execution decisions through direct communication but persist state centrally.
The shared state becomes your source of truth for workflow execution. Any agent can query it to understand current system status. This prevents consistency issues that arise when agents maintain separate state.
Inter-Agent Communication Protocols
Agents need standardized ways to communicate. Ad-hoc message formats lead to integration nightmares as you add more agents.
Message Structure
Every message between agents should include:
Sender identification: Which agent sent this message and what role it plays.
Message type: Request, response, notification, or command. Each type has different handling requirements.
Payload: The actual data or instruction being communicated. Use structured formats like JSON or Protocol Buffers.
Context: Workflow ID, trace ID, and any other identifiers needed to correlate messages with specific tasks.
Timestamp: When the message was created. Critical for debugging timing issues.
Microsoft's Agent Framework implements this through a standardized message envelope. Agents don't need to know details about other agents' internals. They just send and receive properly formatted messages.
Communication Channels
You need reliable transport for agent messages. Don't build your own. Use existing message brokers.
Kafka works well for high-throughput scenarios where agents process streams of events. Each agent subscribes to relevant topics and publishes results to output topics.
Redis Streams provides lower latency for request-response patterns. Good for workflows where agents need quick answers from other agents.
Event-driven architectures using AWS EventBridge or Azure Event Grid let agents react to system events without tight coupling. One agent's output triggers another agent's execution automatically.
Choose based on your latency requirements and existing infrastructure. Don't introduce a new message broker just for agent communication if you already have one in production.
Conversation Protocols
Agents often need multi-turn interactions to complete complex tasks. A query optimization agent might request statistics from a metadata agent, then ask follow-up questions based on the response.
Define conversation protocols that specify:
Initiation: How conversations start and what initial context is required.
Turn-taking: Which agent responds next and how turns are managed.
Termination: When conversations end and what constitutes a complete exchange.
Without these protocols, conversations between agents can get stuck in loops or deadlock waiting for responses that never come.
Agent Specialization Strategies
Different workflow aspects require different types of specialized knowledge.
Domain-Specific Agents
These agents focus on specific technical domains. A schema management agent understands data types, constraints, and evolution patterns. A cost optimization agent knows cloud pricing models and resource utilization patterns.
Build these agents with domain-specific prompts and tools. The schema agent gets tools for querying metadata catalogs and analyzing table statistics. The cost agent accesses billing APIs and resource monitoring systems.
Training approach: Fine-tune smaller models on domain-specific tasks rather than using large general-purpose models. A 7B parameter model fine-tuned on schema management will outperform a 70B general model for that specific task.
Task-Oriented Agents
These agents handle specific workflow tasks regardless of domain. A notification agent sends alerts. A validation agent checks data quality. A scheduler agent manages execution timing.
Task-oriented agents are reusable across different workflows. Your notification agent works the same whether it's alerting about pipeline failures or data quality issues.
Monitoring and Governance Agents
These agents don't directly manipulate workflows. They observe, analyze, and enforce policies.
A lineage tracking agent monitors data flow between systems and maintains governance metadata. A compliance agent checks that workflows follow regulatory requirements. A cost tracking agent watches resource usage and flags anomalies.
These agents run continuously, providing oversight across all workflow activity. They integrate with your existing observability stack to correlate agent actions with system metrics.
Observability for Multi-Agent Systems
When multiple agents collaborate, understanding system behavior gets complicated fast. You can't just look at logs from one agent.
Distributed Tracing
Implement OpenTelemetry tracing across all agents. Each agent operation becomes a span in a larger trace that shows the complete workflow execution.
When a user request triggers five different agents, your trace shows the full path: coordinator receives request, routes to agent A, agent A queries agent B, results flow back up. You see latencies at each step and where bottlenecks occur.
Key metrics to track: Agent-to-agent latency, message queue depths, LLM token usage per agent, decision making time, and overall workflow completion time.
Agent State Visualization
Build dashboards that show which agents are active, what they're working on, and how they're communicating. This gives operators situational awareness when troubleshooting issues.
Your dashboard should answer: Which agents are currently executing tasks? What conversations are in progress? Are any agents stuck waiting for responses? What's the message backlog in each communication channel?
Decision Logging
Agents make autonomous decisions that affect workflow execution. Log every decision with full context: what information the agent had, what options it considered, why it chose a specific action.
When something goes wrong, you need to reconstruct the agent's reasoning. Did it have incomplete information? Did it misinterpret a message? Was its prompt ambiguous?
Store decision logs separately from application logs. They have different retention requirements and query patterns. Operators searching for "why did the system do X" need fast access to decision history.
Governance and Security
Multi-agent systems introduce new security considerations.
Agent Authentication and Authorization
Each agent needs identity. Don't use shared credentials. Give each agent its own service principal or IAM role with minimum required permissions.
The coordinator might have broad permissions to orchestrate workflows, but worker agents should only access resources they specifically need. Your schema analysis agent doesn't need write access to production databases.
Implement agent-to-agent authentication. Verify that messages actually come from the claimed sender. Use signed JWTs or mutual TLS for inter-agent communication.
Access Control Policies
Define what each agent can do and what data it can access. A data quality agent might read from production tables but shouldn't modify them. A schema evolution agent needs write access to metadata catalogs but not raw data.
Policy enforcement points: At the agent level (what tasks an agent accepts), at the resource level (what systems an agent can access), and at the data level (what specific data an agent can see).
Microsoft's Agent Framework includes policy definition capabilities. You specify rules in declarative format that the platform enforces automatically.
Audit Trails
Maintain complete audit logs of agent actions. Compliance requirements often mandate knowing who (or what) accessed data and what they did with it.
Your audit trail needs: agent identity, action taken, resources accessed, decision rationale, timestamp, and outcome. Store this in append-only storage that agents can't modify.
Regulators asking "how was this data used" should get clear answers even when agents made autonomous decisions. The audit trail reconstructs the full chain of actions.
Rate Limiting and Cost Controls
Agents calling LLM APIs can burn through budgets quickly. Implement rate limits per agent and per workflow.
Circuit breakers prevent runaway costs. If an agent hits token limits or makes too many API calls in a time window, it gets throttled or paused. The coordinator handles this gracefully rather than failing the entire workflow.
Track costs by agent so you can optimize. You might discover one agent using 80% of your LLM budget because its prompts are inefficient.
Integration with Orchestration Platforms
Modern orchestration platforms are adding native support for multi-agent systems.
Dagster and Agent-Enhanced Scheduling
Dagster now supports context-aware scheduling where agents analyze pipeline history and business constraints to optimize execution timing. Instead of cron schedules, agents decide when to run based on data freshness, resource availability, and downstream dependencies.
The platform provides APIs for agents to query asset metadata, check partition status, and trigger runs. Agents become first-class participants in the orchestration layer.
Prefect's Dynamic Workflow Modification
Prefect lets agents modify workflows during execution. An agent analyzing a pipeline failure can inject recovery steps or adjust resource allocation without human intervention.
This works through Prefect's state management system. Agents read current workflow state, make decisions, and use Prefect APIs to modify execution graphs. The platform handles state consistency and prevents race conditions.
Flyte's Multi-Agent Task Execution
Flyte supports agent-driven task execution where different tasks in a workflow can be handled by specialized agents. One task uses an SQL optimization agent, another uses a data validation agent.
Flyte manages agent lifecycle and provides communication primitives between agents. It handles failure scenarios where agents become unavailable mid-workflow.
Real-World Implementation Patterns
Pattern 1: Intelligent Pipeline Recovery
When pipelines fail, specialized agents diagnose and fix issues automatically. A failure detection agent identifies the problem type. It routes to specialized recovery agents: retry logic for transient failures, data repair for quality issues, resource adjustment for capacity problems.
The coordinator tracks recovery attempts and escalates to humans when agents can't resolve issues. This reduces mean time to recovery from hours to minutes for common failure scenarios.
Pattern 2: Natural Language Pipeline Management
Engineers describe what they want in plain English. A language understanding agent interprets the request and generates a workflow specification. A validation agent checks feasibility. A scheduling agent determines optimal execution timing. An execution agent runs the pipeline.
Users don't write DAG code anymore. They describe intent. Agents translate that into executable workflows.
Pattern 3: Cross-System Data Movement
Moving data between systems requires coordination across multiple domains. A source agent extracts data using system-specific protocols. A transformation agent applies business rules. A validation agent checks quality. A destination agent loads data with appropriate schema mapping.
Each agent specializes in one system or concern. They coordinate through the message broker without depending on each other's internal implementation.
Challenges and Considerations
Agent Coordination Overhead
More agents mean more communication overhead. Each message adds latency. Too much coordination slows down workflows.
Mitigation: Batch communications where possible. Let agents make local decisions without consulting other agents for routine operations. Only coordinate for complex scenarios that require multiple perspectives.
Debugging Complexity
When something goes wrong in a multi-agent system, root cause analysis gets hard. Was it an individual agent's decision? A communication failure? A timing issue between agents?
Mitigation: Invest heavily in observability from day one. Distributed tracing and decision logging aren't optional. They're fundamental to operating these systems.
Model Consistency
Different agents might use different LLMs or model versions. This can lead to inconsistent behavior across your system.
Mitigation: Standardize on model versions across agents with similar roles. Use model registries to track which models each agent uses. Test multi-agent interactions when updating models.
Prompt Drift
Agent prompts change over time as you tune performance. Changes to one agent's prompts can affect how other agents interpret its messages.
Mitigation: Version control prompts. Test agent interactions after prompt changes. Maintain integration tests that verify multi-agent workflows work correctly.
Getting Started
Start small. Don't try to build a complete multi-agent system on day one.
Phase 1: Pick one workflow that would benefit from intelligent automation. Deploy a single agent that handles one specific task. Get comfortable with agent operations, monitoring, and cost management.
Phase 2: Add a second agent that complements the first. Implement basic communication between them. Learn what coordination patterns work for your use cases.
Phase 3: Introduce a coordinator agent that manages interactions between your specialized agents. Build out observability and governance capabilities.
Phase 4: Expand to multiple workflows and add more specialized agents. By now you understand the operational challenges and have infrastructure in place.
Key Takeaways
Multi-agent orchestration enables enterprises to handle complex data workflows that single agents can't manage effectively. Specialized agents coordinate through standardized protocols to accomplish tasks requiring multiple types of expertise.
Successful implementations require careful attention to coordination patterns, communication protocols, and observability. You can't debug what you can't see.
Start with proven orchestration platforms that are adding agent capabilities rather than building everything from scratch. Dagster, Prefect, and Flyte provide foundations to build on.
Focus on governance and security from the beginning. Agent authentication, authorization, and audit trails aren't afterthoughts. They're core requirements for production systems.
The technology is ready for production use. Companies are already running multi-agent systems at scale. The question isn't whether to adopt this approach but how to implement it effectively for your specific workflows.
References and Further Reading
Microsoft Agent Framework: Official documentation on building multi-agent systems in Azure - https://learn.microsoft.com/en-us/azure/ai-services/agents/
Dagster AI Integration: Documentation on using AI agents with Dagster - https://docs.dagster.io/
Prefect Dynamic Workflows: Guide to building adaptive workflows with Prefect - https://docs.prefect.io/
OpenTelemetry for Distributed Systems: Implementing tracing across services - https://opentelemetry.io/docs/
LangGraph Multi-Agent Patterns: Patterns for building agent systems - https://langchain-ai.github.io/langgraph/



Leave a Comment