From Lake to Warehouse with Apache Doris: Querying Iceberg/Hudi/Hive via Multi-Catalog (and Designing Tiered Storage)
The real-world problem (and why this matters)
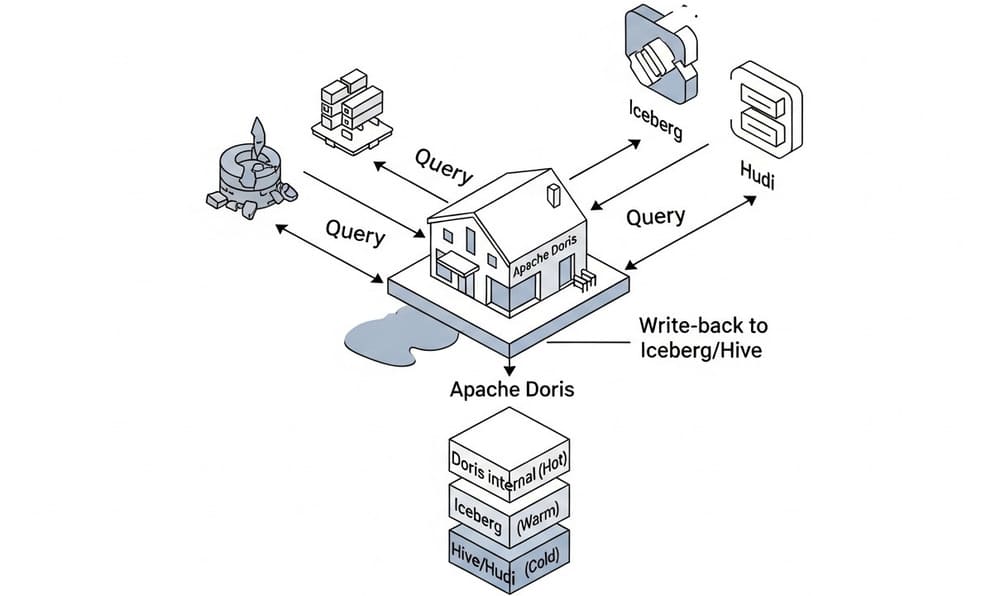
Your data lives in S3/HDFS as Iceberg/Hudi/Hive tables, but product wants sub-second dashboards and easy SQL joins. Re-ingesting everything into a warehouse is slow and pricey. Apache Doris fixes this by letting you mount lake catalogs (Iceberg/Hudi/Hive), query them with ANSI-ish SQL, optionally write back to the lake, and keep “hot” aggregates inside Doris for speed. That’s Multi-Catalog in a nutshell. (Apache Doris)
Concept: Doris Multi-Catalog, visually
Think of Doris as a router + accelerator:
- Catalogs: logical mounts that point to external systems (Iceberg, Hive/Hudi, JDBC, other Doris). You can attach many. Doris auto-discovers databases/tables and lets you join across them. (Apache Doris)
- Access patterns:
- Read Iceberg/Hudi/Hive directly.
- Write to Iceberg (supported), to Hive (supported with the right settings), not to Hudi (query-only). (Apache Doris)
- Control plane: switch catalogs (
SWITCH CATALOG/USE catalog.db) and fully qualify tables (catalog.db.table). (Apache Doris)
Architecture & data flow
- Create Catalogs that point to your lake metadata service (HMS/Glue/REST) and storage (S3/HDFS).
- Query with standard SQL across catalogs.
- Write results back to Iceberg/Hive or land “hot” slices into internal Doris tables.
- Tier data: keep hot aggregates in Doris; keep raw/warm in the lake; exploit Doris’ compute-storage decoupled mode for elasticity and cost. (Apache Doris)
Hands-on: Create the catalogs
Iceberg (HMS or REST)
-- Iceberg via Hive Metastore
CREATE CATALOG ice_ctl PROPERTIES (
'type'='iceberg',
'iceberg.catalog.type'='hms',
'hive.metastore.uris'='thrift://hms:9083'
);
-- Iceberg via REST
CREATE CATALOG ice_rest PROPERTIES (
'type'='iceberg',
'iceberg.catalog.type'='rest',
'uri'='http://iceberg-rest:8181'
);
Doris supports Iceberg with HMS, REST, Hadoop FS (needs warehouse), Glue, DLF—and read & write operations. (Apache Doris)
Hive (and thus Hudi)
-- Hive Catalog (needed for Hive AND Hudi)
CREATE CATALOG hive_ctl PROPERTIES (
'type'='hms',
'hive.metastore.uris'='thrift://hms:9083',
'fs.defaultFS'='hdfs://namenode:8020' -- required if you plan to WRITE via Doris
);
Note the fs.defaultFS property: it’s required for writes to Hive through Doris. Hudi uses the Hive Catalog to read, and write-back to Hudi is not supported. (Apache Doris)
Reference: CREATE CATALOG statement and examples. (Apache Doris)
Querying across the lake (simple and fast)
-- Pick a catalog + db
SWITCH CATALOG ice_ctl; -- or: USE ice_ctl.sales
USE ice_ctl.sales;
-- Explore
SHOW TABLES;
-- Join Iceberg facts with a Hive dimension, fully qualified:
SELECT f.order_id, d.region, f.amount
FROM ice_ctl.sales.fact_orders AS f
JOIN hive_ctl.dim.dim_region AS d
ON f.region_id = d.id
WHERE f.order_dt >= '2025-11-01'
LIMIT 100;
You can switch catalogs or use fully-qualified names (catalog.db.table). (Apache Doris)
Writing back to the lake (Iceberg & Hive)
Option A — Write to Iceberg
Use INSERT INTO/OVERWRITE or CTAS. You can even target branches/tags in Iceberg v2.
-- Write data from Doris internal table to Iceberg
INSERT INTO ice_ctl.analytics.daily_sales (dt, revenue)
SELECT order_dt AS dt, SUM(amount) AS revenue
FROM internal.dw.fact_orders
GROUP BY order_dt;
-- Overwrite a partitioned Iceberg table
INSERT OVERWRITE TABLE ice_ctl.analytics.daily_sales
SELECT dt, revenue FROM internal.dw.daily_sales_stage;
-- Create Iceberg table with CTAS
CREATE TABLE ice_ctl.analytics.top_skus
AS SELECT sku, SUM(qty) AS units
FROM internal.dw.fact_orders
GROUP BY sku;
Doris supports INSERT, INSERT OVERWRITE, and CTAS for Iceberg (including branch/tag writes in newer versions). (Apache Doris)
Option B — Write to Hive
-- Be sure hive catalog was created with fs.defaultFS
INSERT INTO hive_ctl.reports.sales_2025
SELECT * FROM internal.dw.sales_2025_delta;
Hive writes work when the catalog is configured for writing (e.g., fs.defaultFS). Review concurrency/transaction notes when targeting Hive. (Apache Doris)
Cross-catalog copy is just INSERT INTO ... SELECT ... — Doris treats it as a synchronous import with atomic semantics. (Apache Doris)
Operational knobs: metadata cache and REFRESH
Doris caches external metadata (dbs/tables/partitions). When upstream schemas or partitions change and you need immediate visibility, run:
REFRESH CATALOG hive_ctl;
-- or narrower:
REFRESH DATABASE hive_ctl.sales;
REFRESH TABLE hive_ctl.sales.fact_orders;
REFRESH invalidates object caches (partition, schema, file), forcing re-fetch. (Apache Doris)
Patterns for tiered storage (hot → warm → cold)
| Tier | Where it lives | What goes here | Why |
|---|---|---|---|
| Hot | Doris internal tables (compute-storage decoupled for elasticity) | Aggregates, recent facts, MV-accelerated rollups | Sub-second BI, isolated compute groups, low cost with object storage + file cache. (Apache Doris) |
| Warm | Iceberg in the lake (S3/HDFS) | Canonical history, CDC-conformed facts | Open table format, ACID, partition evolution; Doris reads/writes for ETL/ELT. (Apache Doris) |
| Cold | Hive/Hudi datasets | Legacy/parquet/orc zones, change logs | Cheap retention; read via Hive Catalog; Hudi is read-only from Doris. (Apache Doris) |
Rules of thumb
- Keep hot aggregates and current few days/weeks in Doris; schedule INSERT INTO Iceberg for durable history. (Apache Doris)
- Use Iceberg as the system of record for warehouse-grade tables you need to share with other engines. (Apache Doris)
- Use REFRESH when you add partitions or schema changes and need them visible now. (Apache Doris)
- For elasticity/cost, consider compute-storage decoupled deployments (object storage + file cache). (Apache Doris)
Best practices (mid-level engineer edition)
- Model for pruning in the lake (partition by date/bucket transforms in Iceberg), then push down filters from Doris. (Apache Doris)
- Prefer Iceberg Catalog over accessing Iceberg via Hive Catalog to avoid compatibility quirks. (Apache Doris)
- For Hive writes, include
fs.defaultFSand review Hive transactional caveats; non-ACID tables are typically simpler for append/overwrite from Doris. (Apache Doris) - Validate cross-catalog moves with small batches first;
INSERT OVERWRITEcarefully targets only the affected partitions. (Apache Doris) - Observe catalog health with
SHOW CATALOGS,SHOW CATALOG <name>, andCATALOGS()TVF when available. (Apache Doris)
Common pitfalls (and how to dodge them)
- “My new table isn’t visible.” You likely hit cache TTL—use
REFRESH CATALOG/DB/TABLE. (Apache Doris) - “INSERT to Hive failed.” Missing or wrong
fs.defaultFSor storage credentials on the catalog. (Apache Doris) - “Can I write to Hudi?” Not from Doris today—Hudi is read-only via the Hive Catalog. (Apache Doris)
- Branching semantics (Iceberg). If you’re using branches/tags, ensure you target them explicitly (
table@branch(...)). (Apache Doris)
Summary & call-to-action
Multi-Catalog turns Doris into a pragmatic lakehouse router: mount Iceberg/Hive/Hudi, query with SQL, write back to Iceberg/Hive, and tier data for cost/speed. Start by creating Iceberg + Hive catalogs, REFRESH them, and run one cross-catalog INSERT to prove out your hot/warm/cold design.
Your next move: Pick one KPI. Materialize a hot aggregate in Doris, keep the raw in Iceberg, and wire a nightly INSERT OVERWRITE to maintain it. Measure latency + cost—then scale out.
Internal link ideas (official docs)
- Data Catalog Overview — basics of Multi-Catalog, access patterns, and types. (Apache Doris)
- CREATE CATALOG — syntax and permission requirements. (Apache Doris)
- Iceberg Catalog — config, reads/writes, CTAS, branches/tags. (Apache Doris)
- Hive Catalog — config, supported storages, write requirements (
fs.defaultFS). (Apache Doris) - Hudi Catalog — reuse Hive Catalog; read-only from Doris. (Apache Doris)
- REFRESH & Metadata Cache — invalidate catalog/db/table caches. (Apache Doris)
- USE / SWITCH CATALOG — switching catalogs and fully qualified names. (Apache Doris)
- Compute-Storage Decoupled Overview — when to use decoupled mode for tiered storage. (Apache Doris)
Bonus: quick command crib sheet
-- Switch or target explicitly
SWITCH CATALOG ice_ctl; -- or USE ice_ctl.sales
SELECT * FROM ice_ctl.sales.tbl; -- fully qualified
-- Make new tables in Iceberg
CREATE TABLE ice_ctl.analytics.daily (... ) PROPERTIES('write-format'='parquet');
-- Move data between catalogs (atomic)
INSERT INTO ice_ctl.analytics.daily SELECT * FROM internal.dw.daily;
-- Force metadata refresh
REFRESH CATALOG ice_ctl;
REFRESH TABLE hive_ctl.sales.fact_orders;







Leave a Reply