Keboola: The Managed Data Platform You Probably Haven’t Heard Of
Introduction
Most data engineers know Airflow, Snowflake, and dbt. They’re the tools everyone talks about. But there’s a category of platforms that takes a different approach. Instead of assembling your own data stack, these platforms give you everything in one package.
Keboola is one of them.
It’s a fully managed data operations platform. No infrastructure to set up. No orchestration to configure. No connectors to build. You get extraction, transformation, orchestration, and deployment in a single environment.
This sounds appealing, especially to smaller teams or businesses without dedicated data engineering resources. But managed platforms come with trade-offs. Less flexibility, potential vendor lock-in, and costs that can escalate.
This article breaks down what Keboola actually is, who it works for, and when you should consider it over building your own stack.
What is Keboola?
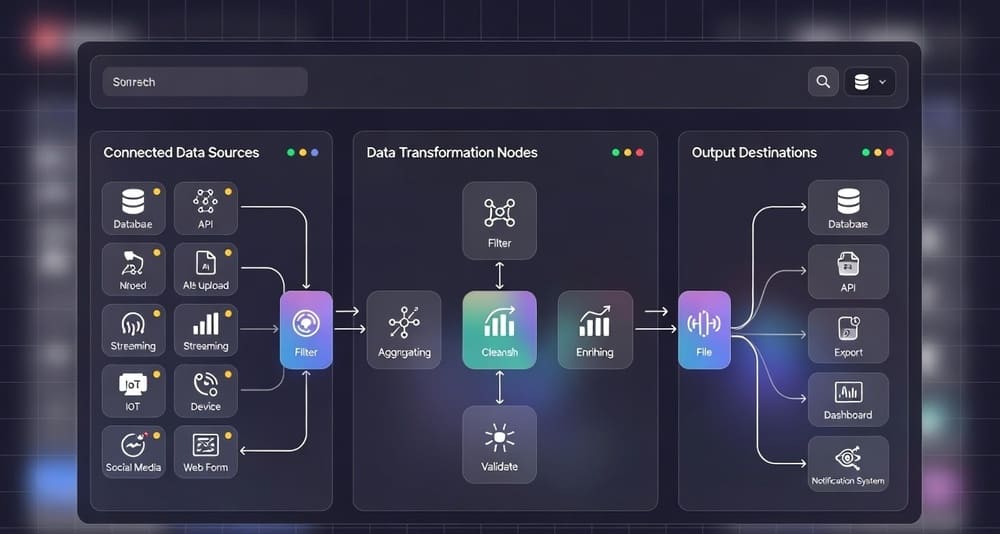
Keboola is a cloud-based data platform that handles the full data pipeline lifecycle. You connect data sources, transform data, and push results to destinations. All through a web interface.
The core components include:
Extractors pull data from various sources. APIs, databases, file storage, SaaS applications. Keboola has pre-built connectors for common systems.
Transformations process your data. You write SQL, Python, or R. Keboola executes these in isolated environments.
Writers send data to destinations. Data warehouses, BI tools, reverse ETL targets, applications.
Orchestrator manages workflow scheduling and dependencies. You define when things run and in what order.
Data Catalog tracks lineage and metadata. You can see where data comes from and where it goes.
The platform runs everything. You don’t manage servers, containers, or job queues. You define what you want to happen, Keboola handles execution.
The Managed Platform Approach
Keboola represents a different philosophy than tools like Airflow or Prefect. Instead of giving you building blocks, it gives you a complete system.
Traditional data stacks require assembly. You pick an orchestrator, choose a warehouse, select transformation tools, build connectors. Each piece needs configuration, monitoring, and maintenance.
Managed platforms bundle everything. The advantage is speed. You can build pipelines faster because infrastructure decisions are already made. The disadvantage is flexibility. You work within the constraints of what the platform offers.
This trade-off matters more as teams grow. A three-person team might love the simplicity. A 30-person data engineering team might find it limiting.
Core Features and Capabilities
Data Extraction
Keboola provides pre-built extractors for common data sources. Databases like PostgreSQL, MySQL, and MongoDB. SaaS applications like Salesforce, Google Analytics, and HubSpot. Cloud storage like S3 and Google Cloud Storage.
Each extractor has configuration options. You specify credentials, select tables or endpoints, and set extraction parameters. The platform handles the actual extraction and loading.
For sources without pre-built extractors, you can use generic extractors or custom components. Generic extractors work with standard protocols like REST APIs or JDBC connections. Custom components let you run your own code.
The extraction layer handles incremental loading, schema detection, and error handling. You don’t write code to poll APIs or manage connection pools.
Data Transformation
Transformations in Keboola use familiar languages. SQL transformations run on Snowflake backends. Python and R transformations execute in sandboxed environments.
You write transformation logic in the web interface or sync from Git repositories. Each transformation can reference input tables and produce output tables. Keboola manages the data movement between transformations.
The SQL transformations support most standard SQL operations. You can join tables, aggregate data, and build derived datasets. The Python and R environments include common libraries for data processing.
Version control is built in. Every change to a transformation is tracked. You can roll back to previous versions if needed.
Orchestration and Scheduling
The orchestration layer manages when workflows run. You create orchestrations that chain together extractors, transformations, and writers.
Scheduling works with cron-like syntax or time-based triggers. You can set up hourly, daily, or custom schedules. The system handles retries if steps fail.
Dependencies between components are explicit. If transformation B needs data from extractor A, you define that relationship. The orchestrator ensures proper execution order.
Monitoring shows what’s running, what failed, and what succeeded. Alerts notify you when workflows have problems.
Data Lineage and Governance
Keboola tracks data lineage automatically. You can see which transformations use which sources, and which outputs depend on which transformations.
This helps with impact analysis. Before changing a data source, you can see everything downstream that might break.
The platform also provides metadata management. You can add descriptions, tags, and documentation to datasets and transformations. This helps teams understand what data exists and how to use it.
Access control manages who can view, edit, or execute components. You can restrict sensitive data to specific users or teams.
Who Uses Keboola?
Keboola targets a specific user profile. The typical customer is a mid-sized business that needs data pipelines but doesn’t want to build a data platform from scratch.
Marketing teams use it to consolidate data from advertising platforms, analytics tools, and CRM systems. They build dashboards without relying on engineering teams.
Business intelligence teams at companies without dedicated data engineering use Keboola to prepare data for analysis. They can build pipelines using SQL without managing infrastructure.
Smaller SaaS companies use it to build customer-facing analytics. They pipe usage data through transformations and surface insights to customers.
Data consultancies use Keboola to deliver solutions faster. They can set up client pipelines without custom engineering work.
The common thread is teams that value speed over customization. They want working pipelines quickly and are willing to accept platform constraints.
Strengths of the Platform
Fast Time to Value
The biggest advantage is how quickly you can go from zero to working pipelines. No infrastructure setup. No decisions about which tools to use. You create an account and start building.
For teams without data engineering resources, this matters enormously. A business analyst who knows SQL can build functional data pipelines in days, not months.
Reduced Operational Burden
Keboola handles all infrastructure management. No servers to patch. No databases to tune. No orchestration systems to monitor.
This frees up time for actual data work instead of platform maintenance. Small teams especially benefit since they don’t have dedicated platform engineers.
Pre-Built Integrations
The library of extractors and writers covers common use cases. Most businesses use a handful of SaaS tools, databases, and analytics platforms. Keboola probably has connectors for them.
This eliminates the need to build and maintain custom integration code. Updates to source APIs get handled by Keboola, not your team.
Built-In Best Practices
The platform enforces certain patterns. Transformations run in isolation. Data lineage is tracked automatically. Changes are versioned.
These are things you should do anyway, but implementing them yourself takes work. Keboola makes them default behavior.
Limitations and Trade-offs
Platform Lock-In
Everything runs on Keboola’s infrastructure. Your workflows are defined in their system. Moving to a different platform means rebuilding pipelines from scratch.
This is the classic build versus buy trade-off. Managed platforms are faster to start but harder to leave.
Limited Flexibility
You work within the constraints of what Keboola supports. Want to use a specific Python library? It needs to be available in their environment. Want to optimize a particular transformation? You’re limited to the optimization options they expose.
Advanced data engineering teams often hit these walls. The platform works great for standard patterns but struggles with edge cases.
Cost Structure
Keboola pricing is based on usage. Credits get consumed by extraction volume, transformation runtime, and storage.
For small workloads, this can be economical. But costs can grow quickly with scale. A team processing terabytes daily might find self-hosted solutions more cost-effective.
The pricing model also makes cost prediction harder. Unlike fixed infrastructure costs, usage-based pricing varies month to month.
Less Control Over Performance
You can’t tune the underlying infrastructure. If a transformation runs slowly, your options are limited. You can optimize the SQL or Python code, but you can’t adjust resource allocation or execution engines.
Teams with performance-critical workloads might find this frustrating.
Smaller Ecosystem
Compared to widely-used tools like Airflow or dbt, Keboola has a smaller community. Fewer blog posts, fewer Stack Overflow answers, fewer shared solutions.
This means more reliance on official documentation and support. You’re less likely to find someone who has solved your exact problem before.
When Keboola Makes Sense
Keboola is a good fit in specific scenarios.
Small to medium businesses without data engineering teams. If you have business analysts or data analysts who know SQL, they can build pipelines without engineering help.
Rapid prototyping and MVPs. When you need to validate a data product idea quickly, Keboola lets you build without infrastructure investment.
Teams with standard use cases. If your needs align with common patterns (extract from APIs, transform with SQL, load to BI tools), Keboola handles it well.
Organizations that value predictability. Managed platforms reduce the number of things that can go wrong. Less surface area for operational issues.
Projects with tight deadlines. When time to market matters more than optimal architecture, Keboola accelerates delivery.
When to Choose Something Else
Keboola is not the right choice in other scenarios.
Large-scale data processing. Teams processing terabytes daily will find costs and performance limitations. Self-hosted solutions with optimized infrastructure make more sense.
Complex custom logic. If your transformations require specialized libraries, specific runtime environments, or integration with proprietary systems, the platform constraints become limiting.
Teams with strong engineering resources. If you have data engineers who can build and maintain a data platform, you’ll likely outgrow Keboola’s flexibility. The trade-off shifts when engineering time is abundant.
Cost-sensitive, high-volume workloads. Usage-based pricing can become expensive at scale. Running your own infrastructure might cost less.
Organizations requiring full control. Regulated industries or companies with strict data governance might need more control than a managed platform provides.
How Keboola Compares to Alternatives
Keboola vs. Fivetran + dbt + Airflow
This comparison comes up often. The modern data stack typically combines Fivetran for extraction, dbt for transformation, and Airflow for orchestration.
Keboola advantage: Single platform, faster setup, less operational overhead.
Modern stack advantage: Best-of-breed tools, more flexibility, larger communities, potentially lower costs at scale.
The decision comes down to team capabilities and scale. Keboola wins on simplicity. The modern stack wins on power and flexibility.
Keboola vs. AWS Glue or Azure Data Factory
Cloud provider ETL services offer managed orchestration and transformation.
Keboola advantage: More pre-built connectors, easier for non-engineers, cross-cloud support.
Cloud services advantage: Tighter integration with cloud ecosystems, potentially lower costs within the same cloud, more control over compute resources.
Choose cloud services if you’re committed to one cloud provider. Choose Keboola if you want a more complete, user-friendly platform.
Keboola vs. Other Managed Platforms (Matillion, Stitch, etc.)
Several platforms compete in this space. Matillion targets data warehouse ETL. Stitch focuses on data replication.
Keboola is broader. It covers more of the data pipeline lifecycle. But this breadth means it’s less specialized than tools focused on specific problems.
Real-World Use Cases
E-commerce Analytics Consolidation
An online retailer used Keboola to consolidate data from Shopify, Google Ads, Facebook Ads, and their email platform. They transformed the data using SQL and pushed results to Tableau.
Before Keboola, they exported CSV files manually and combined them in spreadsheets. The manual process took days each month.
With Keboola, the pipeline runs automatically. Marketing teams access fresh data daily. They built the entire pipeline in two weeks.
SaaS Customer Health Scoring
A B2B SaaS company built a customer health scoring system using Keboola. They extracted product usage data, support ticket data, and payment information.
Transformations calculated engagement scores, identified at-risk customers, and generated alerts. Results fed into their CRM and customer success platform.
The alternative was building a custom data platform. With limited engineering resources, that would have taken months. Keboola let them launch in weeks.
Multi-Source Reporting for Agencies
A marketing agency manages campaigns for dozens of clients. Each client uses different tools. Google Ads, LinkedIn, various analytics platforms.
The agency uses Keboola to build standardized reporting pipelines. They extract data from each client’s tools, transform it into a common schema, and generate reports.
This standardization lets them scale reporting without custom work for each client.
Getting Started Considerations
If you’re evaluating Keboola, consider these factors.
Trial the platform with a real use case. Build an actual pipeline you need. This reveals whether the platform fits your needs better than reading documentation.
Understand the pricing model. Run a realistic workload and track credit consumption. Extrapolate to production volumes. Compare to alternatives.
Check connector availability. Make sure pre-built extractors exist for your key data sources. Evaluate how easy it is to build custom connectors if needed.
Test transformation capabilities. Write transformations similar to your production needs. Check if the SQL or Python environments support what you require.
Consider exit strategy. How would you migrate off the platform if needed? Where would your data and logic go?
Evaluate support options. Understand what support is available. Response times, documentation quality, and community resources.
The Future of Managed Data Platforms
Managed platforms like Keboola represent one vision of the data stack’s future. Instead of assembling components, teams get complete solutions.
The counter-trend is the modern data stack. Best-of-breed tools that integrate through standard interfaces. Open source, flexible, customizable.
Both approaches will coexist. The right choice depends on your team, scale, and priorities.
Expect managed platforms to improve in flexibility. Better support for custom code, more integration options, more control over execution. They’re addressing their limitations.
At the same time, open source stacks are getting easier. Better tooling, clearer patterns, managed hosting options. They’re addressing the complexity that makes managed platforms attractive.
The gap between the two approaches is narrowing.
Key Takeaways
Keboola is a fully managed data operations platform. It handles extraction, transformation, orchestration, and data delivery in one environment.
The main advantage is speed and simplicity. Teams can build data pipelines quickly without managing infrastructure. This works best for small to medium businesses and standard use cases.
The main disadvantages are flexibility limitations and potential cost at scale. Advanced teams will hit constraints. High-volume workloads might be expensive.
Keboola makes sense when you value time to market over customization. When you need working pipelines fast and don’t have dedicated platform engineers.
It’s less suitable for large-scale processing, complex custom logic, or teams with strong engineering capabilities who can build optimized solutions.
Like all build versus buy decisions, evaluate based on your specific situation. What you’re building, who’s building it, and what constraints matter most.
Tags: Keboola, managed data platform, data pipeline platform, ETL platform, data operations, no-code data tools, cloud data platform, data integration, business intelligence, data pipeline tools, data orchestration, SaaS data tools, data platform comparison, modern data stack alternatives



