Data Vault: The Agile and Resilient Architecture for Enterprise Data Warehousing
In the ever-evolving landscape of data engineering, organizations face mounting challenges: exponentially growing data volumes, increasingly diverse data sources, and business requirements that change at unprecedented speed. Traditional data warehouse architectures often struggle to adapt to these dynamics, creating bottlenecks that impede an organization’s analytical capabilities. Enter Data Vault—a revolutionary approach to data warehousing that prioritizes adaptability, scalability, and historical accuracy while maintaining the performance needed for modern business intelligence.
The Genesis of Data Vault
The Data Vault methodology emerged in the early 2000s through the work of Dan Linstedt, who sought to address the limitations of existing data warehouse architectures. Linstedt recognized that traditional approaches like Kimball’s dimensional modeling and Inmon’s normalized data warehouse weren’t sufficiently addressing the need for both stability and flexibility in enterprise data environments.
Linstedt’s innovation lay in creating a “hybrid” approach that combined the historical tracking capabilities of a normalized model with the performance characteristics of dimensional models, while adding unique adaptability features not present in either. The result was Data Vault—a methodology that has grown from an innovative concept to a widely-adopted enterprise standard for organizations dealing with complex, changing data environments.
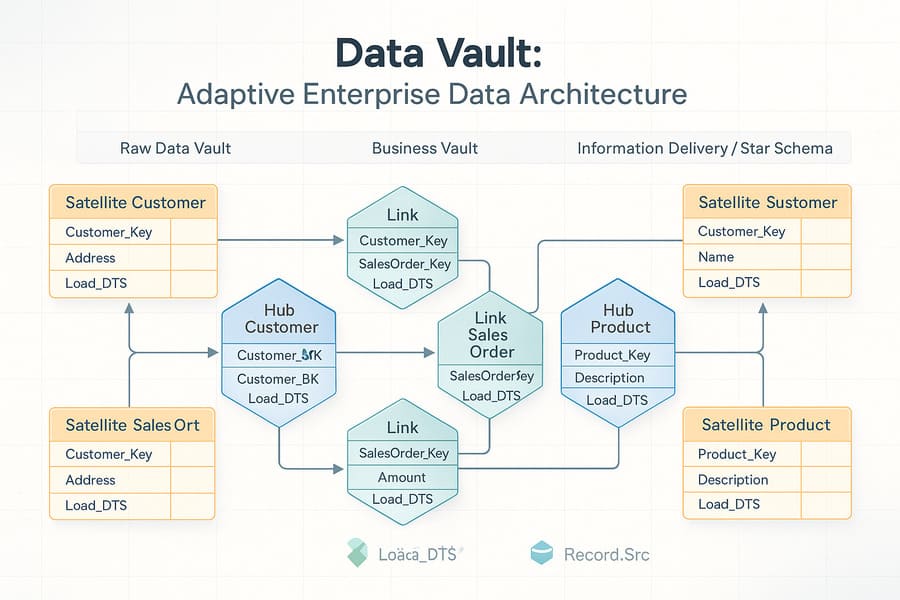
Core Components of Data Vault Architecture
The Data Vault model consists of three primary structural components, each serving a specific purpose in the overall architecture:
1. Hubs: The Business Keys
Hubs represent business entities and contain nothing more than business keys and their metadata. They serve as the stable anchors of the Data Vault model.
Key Characteristics:
- Contain only business keys (natural keys from source systems)
- Include minimal metadata (load dates, record sources, etc.)
- Remain stable even as the business evolves
- Connect related data across the enterprise
- Represent “what” the business tracks
Example Hub Table: HUB_CUSTOMER
HUB_CUSTOMER_SK (Surrogate Key)
CUSTOMER_BK (Business Key)
LOAD_DATE
RECORD_SOURCE
2. Links: The Relationships
Links capture the relationships between business entities (Hubs), representing associations and transactions between them.
Key Characteristics:
- Connect two or more Hubs together
- Capture point-in-time relationships
- Contain only foreign keys to Hubs and metadata
- Represent “how” business entities interact
- Can form hierarchies, networks, and transactions
Example Link Table: LINK_CUSTOMER_ORDER
LINK_CUSTOMER_ORDER_SK (Surrogate Key)
HUB_CUSTOMER_SK (Foreign Key)
HUB_ORDER_SK (Foreign Key)
LOAD_DATE
RECORD_SOURCE
3. Satellites: The Context
Satellites contain descriptive attributes and context for Hubs and Links, capturing how this information changes over time.
Key Characteristics:
- Store descriptive attributes and context
- Always attached to a Hub or Link
- Contain full history through effective dating
- Represent “when” and “why” details about entities
- Can be organized by rate of change, source system, or subject area
Example Satellite Table: SAT_CUSTOMER_DETAILS
SAT_CUSTOMER_DETAILS_SK (Surrogate Key)
HUB_CUSTOMER_SK (Foreign Key)
LOAD_DATE
EFFECTIVE_FROM_DATE
EFFECTIVE_TO_DATE
HASH_DIFF (Hash of all attributes for change detection)
RECORD_SOURCE
CUSTOMER_NAME
CUSTOMER_EMAIL
CUSTOMER_PHONE
CUSTOMER_ADDRESS
... other attributes
Fundamental Principles of Data Vault
Beyond its structural components, the Data Vault methodology is guided by key principles that inform its implementation:
1. Separation of Concerns
The strict separation between business keys (Hubs), relationships (Links), and descriptive context (Satellites) creates a modular architecture where each component can evolve independently.
This separation allows for:
- Parallel loading processes
- Independent scaling of different components
- Isolation of changes to specific components
- Clear boundaries of responsibility in the data model
2. Immutable History and Auditability
The Data Vault model captures a complete, immutable record of all data over time, creating a full audit trail of changes. This is achieved through:
- Append-only operations (no updates or deletes to existing records)
- Effective dating to track validity periods
- Source system attribution for all records
- Hash keys for change detection and data lineage
This approach ensures compliance with regulations requiring historical accuracy and supports time-travel queries that reconstruct the state of data at any point in time.
3. Adaptability to Change
Perhaps the most distinctive characteristic of Data Vault is its resilience in the face of change:
- New data sources can be integrated without restructuring existing tables
- Changes to business entities require only new or modified Satellites
- Business relationship changes are accommodated by creating new Links
- Source system changes are isolated to specific components
This adaptability dramatically reduces the maintenance burden associated with traditional data warehouse architectures when business requirements evolve.
4. Raw Data Preservation
Data Vault maintains the raw, unaltered source data, distinguishing between storage (preserving the data as delivered) and presentation (transforming data for consumption):
- Source data is preserved exactly as received
- Business rules are applied during the presentation layer creation
- Multiple interpretations of the same data can coexist
- Source system errors can be corrected without losing the original values
The Data Vault Methodology in Practice
While the Data Vault model forms the core of the approach, the broader Data Vault methodology encompasses a comprehensive set of practices for implementing and maintaining enterprise data warehouses.
The Three-Layer Architecture
Most Data Vault implementations follow a three-layer architecture:
1. Raw Data Vault (Stage 0)
The raw staging layer that captures data directly from source systems with minimal transformation:
- Simple technical transformations only (data type conversions)
- No business rules applied
- Rapid loading with minimal processing
- Complete source data preservation
2. Business Vault (Stage 1)
An optional layer that applies business rules while maintaining the Data Vault structure:
- Business-specific calculations and derivations
- Cleansed and standardized values
- Integrated data across sources
- Problem resolution and harmonization
3. Information Delivery (Stage 2)
The presentation layer that transforms Data Vault structures into consumption-ready formats:
- Star schemas for business intelligence tools
- Subject-specific data marts
- Aggregated summary tables
- API endpoints for applications
Loading Patterns and ETL Considerations
Data Vault implementations leverage specific ETL/ELT patterns that align with the architecture:
Parallel Processing
The modular nature of Data Vault enables highly parallel loading:
- Hub tables can be loaded simultaneously
- Link tables can be processed once their related Hubs exist
- Satellites can be loaded in parallel once their parent Hub or Link is available
- Different source systems can be processed independently
Hash Keys for Performance
Many Data Vault implementations use hash keys rather than sequence-generated surrogate keys:
- MD5 or SHA-1 hashes of business keys create deterministic surrogate keys
- Hash keys eliminate lookups during the loading process
- Hash differences efficiently detect changes in Satellite records
- Distributed processing becomes simpler without centralized sequence generators
Batch vs. Real-Time Loading
The Data Vault model supports both batch and real-time/near-real-time loading scenarios:
- Traditional batch ETL for periodic processing
- Micro-batching for near-real-time requirements
- Stream processing for true real-time Data Vault loading
- Hybrid approaches combining different loading cadences
Comparing Data Vault to Other Data Warehouse Architectures
To appreciate the unique value proposition of Data Vault, it’s helpful to compare it with other common data warehouse architectures:
Data Vault vs. Kimball Dimensional Model
| Aspect | Data Vault | Kimball Star Schema |
|---|---|---|
| Primary Focus | Adaptability and auditability | Query performance and usability |
| Structure | Hubs, Links, Satellites | Fact and dimension tables |
| Historical Tracking | Comprehensive by design | Requires SCD techniques |
| Schema Complexity | More complex physical model | Simpler query structures |
| Change Management | Highly adaptable to new sources | Requires dimensional updates |
| Loading Process | Highly parallelizable | More sequential dependencies |
| End-User Access | Typically through information marts | Direct access common |
Data Vault vs. Inmon Corporate Information Factory
| Aspect | Data Vault | Inmon 3NF |
|---|---|---|
| Normalization Level | Hybridized approach | Highly normalized |
| Historical Tracking | Built into structure | Typically uses separate history tables |
| Integration Point | Integration through Links | Integration in normalized tables |
| Adaptability | Designed for change | Can be rigid after initial design |
| Performance | Better than 3NF for many queries | Often requires performance layers |
| Auditability | Complete by design | Requires additional tracking |
| Implementation Speed | Can be incrementally deployed | Often requires full upfront design |
Real-World Data Vault Implementation Example
To illustrate how Data Vault works in practice, consider a retail banking scenario where customer, account, and transaction data need to be integrated from multiple systems.
Core Business Entities (Hubs)
- HUB_CUSTOMER: Contains unique customer identifiers
- HUB_ACCOUNT: Contains unique account identifiers
- HUB_TRANSACTION: Contains unique transaction identifiers
- HUB_PRODUCT: Contains unique product identifiers
- HUB_BRANCH: Contains unique branch identifiers
Key Relationships (Links)
- LINK_CUSTOMER_ACCOUNT: Relates customers to their accounts
- LINK_ACCOUNT_TRANSACTION: Relates accounts to transactions
- LINK_CUSTOMER_BRANCH: Relates customers to their home branches
- LINK_ACCOUNT_PRODUCT: Relates accounts to product types
Context and Attributes (Satellites)
- SAT_CUSTOMER_DEMOGRAPHICS: Customer personal information
- SAT_CUSTOMER_CONTACT: Customer contact details
- SAT_ACCOUNT_DETAILS: Account status, dates, settings
- SAT_TRANSACTION_DETAILS: Transaction amounts, types, statuses
- SAT_BRANCH_DETAILS: Branch location, hours, services
- SAT_PRODUCT_DETAILS: Product features, terms, conditions
This structure allows the bank to:
- Track changing customer information over time
- Maintain relationships between customers and multiple accounts
- Record all transactions with their complete context
- Adapt to new product types without restructuring
- Add new data sources (like mobile banking) incrementally
When a new source system is introduced (such as a new mobile banking platform), the Data Vault model can easily accommodate it by:
- Adding new Satellites for unique attributes
- Connecting existing Hubs to the new data through Links
- Potentially creating new Hubs only for entirely new business entities
Technical Implementation Considerations
Implementing a Data Vault requires careful attention to several technical aspects:
Performance Optimization
While Data Vault prioritizes flexibility over raw query performance, several techniques can optimize speed:
- Point-in-Time (PIT) tables: Prebuild tables that join Hubs and their Satellites for specific timestamps
- Bridge tables: Create shortcuts across complex relationships
- Information mart layers: Create performance-optimized star schemas for reporting
- Materialized views: Use database features to precompute common joins
- Columnar storage: Leverage column-oriented storage for analytical queries
- Batch pre-calculation: Perform complex calculations during load rather than query time
Scalability Architecture
The Data Vault model scales exceptionally well in modern distributed environments:
- MPP databases: Leverage massive parallel processing platforms
- Cloud-native implementation: Utilize elastic scaling for variable workloads
- Distributed processing: Hadoop/Spark ecosystems for processing massive data volumes
- Separate storage/compute: Modern cloud data warehouses that separate storage from processing
Automation and Metadata Management
Given the larger number of tables in a Data Vault model, automation becomes essential:
- Model generation: Automated creation of Data Vault structures from source metadata
- ETL/ELT generation: Pattern-based code generation for loading processes
- Documentation generation: Automated lineage and metadata documentation
- Testing frameworks: Systematic validation of data integrity and completeness
When to Choose Data Vault
Data Vault isn’t universally the best choice for every scenario. Here’s guidance on when it’s particularly valuable:
Ideal Use Cases
- Enterprise Data Warehouses: Organizations integrating data from many disparate systems
- Highly Regulated Industries: Environments requiring complete audit trails and historical accuracy (finance, healthcare, insurance)
- Volatile Business Environments: Organizations experiencing frequent mergers, acquisitions, or system changes
- Long-Term Data Retention Requirements: Cases where historical context must be maintained for extended periods
- Multi-Phase Data Integration: Projects requiring incremental delivery of value while accommodating future expansion
Less Suitable Scenarios
- Simple, Stable Data Environments: Organizations with few source systems and minimal change
- Small-Scale Analytics: Departmental or project-specific data marts with narrow scope
- Real-Time Dashboard Focus: Use cases requiring direct, sub-second query response without a presentation layer
- Limited Development Resources: Teams without capacity to implement and maintain the more complex architecture
Evolving Trends in Data Vault Implementation
The Data Vault methodology continues to evolve, with several emerging trends:
Data Vault 2.0
Dan Linstedt’s updated methodology incorporates:
- Hash key usage for performance optimization
- Big Data integration patterns
- Automation frameworks
- NoSQL implementation approaches
- Machine learning integration
Cloud-Native Data Vault
Implementation patterns specialized for cloud environments:
- Serverless ETL for Data Vault loading
- Object storage for raw data persistence
- Elastic compute for variable workloads
- Cloud-specific optimization techniques
- Pay-per-query economic models
Virtualized Data Vault
Logical implementation approaches that don’t physically materialize all structures:
- Data virtualization layers creating Data Vault views
- Hybrid physical/virtual implementations
- Query optimization for virtualized models
- Real-time federated Data Vault queries
Data Vault and Data Mesh Integration
Emerging patterns combining Data Vault with Data Mesh concepts:
- Domain-oriented Data Vault structures
- Product thinking for Data Vault information delivery
- Self-service capabilities on Data Vault foundations
- Distributed ownership models for Data Vault components
Implementation Strategy and Best Practices
For organizations considering Data Vault, these best practices help ensure success:
Start with Business Questions
Begin with clear understanding of the analytical needs:
- Identify key business questions that need answering
- Map required data sources to these questions
- Determine historical requirements for each data element
- Establish priority business entities and relationships
Implement Incrementally
Data Vault particularly shines with incremental implementation:
- Begin with core business entities and minimal context
- Deliver value through early information marts
- Add sources and relationships in planned phases
- Expand historical depth as needs evolve
Invest in Automation
Given the structural complexity, automation is essential:
- Automated code generation for table creation
- Pattern-based ETL/ELT implementation
- Metadata-driven testing and validation
- Documentation generation and maintenance
Create a Center of Excellence
Success with Data Vault requires organizational support:
- Establish consistent standards and patterns
- Develop reusable templates and processes
- Build internal knowledge through training
- Share lessons learned and improvements
Conclusion: The Strategic Value of Data Vault
Data Vault represents more than just another data modeling technique—it embodies a philosophical approach to enterprise data management that values adaptability, historical accuracy, and scalability. In the age of digital transformation where change is the only constant, Data Vault provides a resilient foundation for organizations seeking to turn their diverse, complex data into a strategic asset.
The methodology’s emphasis on separating business keys, relationships, and context creates an architecture that can evolve alongside the business while maintaining the immutable history needed for compliance and analysis. While requiring more initial complexity than traditional approaches, Data Vault delivers long-term value through reduced maintenance costs, greater agility in responding to change, and the ability to provide a single, auditable version of enterprise truth.
For organizations struggling with data integration challenges, frequent source system changes, or the need to maintain accurate historical context, Data Vault offers a proven methodology that transforms data warehousing from a brittle infrastructure liability into a flexible competitive advantage.
Keywords: Data Vault, data warehouse architecture, Dan Linstedt, hub entities, link relationships, satellite tables, enterprise data integration, adaptive data modeling, business key management, historical data tracking, auditability, data lineage, agile data warehousing, raw vault, business vault, information delivery, hash keys, parallel loading, data warehouse automation, point-in-time tables
Hashtags: #DataVault #DataWarehousing #DataArchitecture #DataEngineering #EnterpriseData #DataIntegration #DataModeling #HistoricalTracking #BusinessIntelligence #Auditability #DataLineage #AgileData #HubLinkSatellite #BigData #DataStrategy #ETL



