Materialized Views in QuestDB: Real-Time Rollups Without a Lambda Architecture Meta (155–160 chars):Precompute time-series rollups in QuestDB with materialized views.…
Read More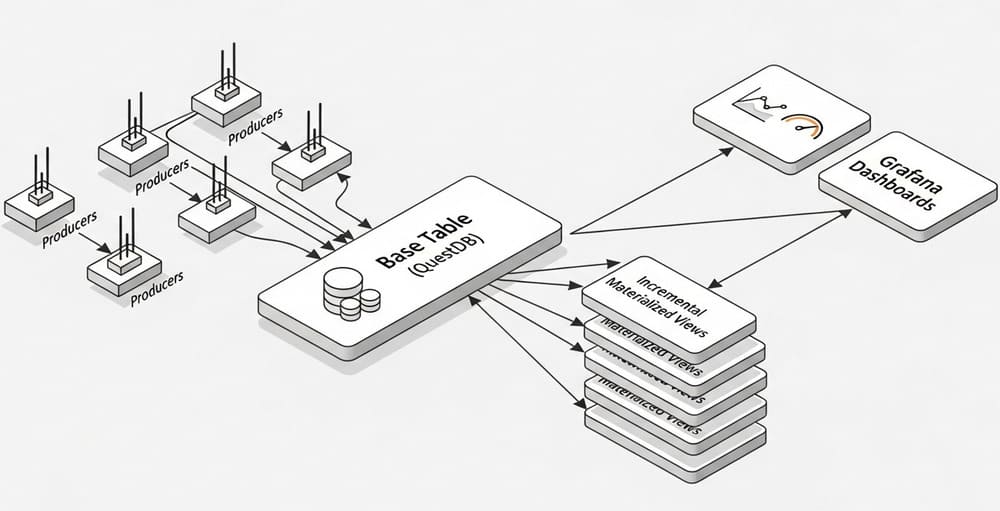
Materialized Views in QuestDB: Real-Time Rollups Without a Lambda Architecture Meta (155–160 chars):Precompute time-series rollups in QuestDB with materialized views.…
Read More
Terraform vs Ansible: Choosing the Right Tool for Infrastructure Automation Introduction: Infrastructure as Code has become standard practice. But choosing…
Read More
Designing SLIs and SLOs for Data Pipelines: A Practical Guide for Data Engineers If your data platform “looks fine” in…
Read More
Terraform vs CloudFormation: Which Infrastructure Tool Actually Fits Your AWS Workflow Introduction: Managing AWS infrastructure through code sounds simple until…
Read More
Vector Databases in Production: What ML Engineers Need to Know in 2025 Why This Article Matters If you’re building AI…
Read More
Query Plans that Don’t Lie: Building a Performance Review with pg_stat_statements Hook: Your app got slower after the last release,…
Read MoreFrom SQL Agent to Managed Workflows: Job Orchestration Choices for Azure SQL You’re leaving on-prem SQL Server Agent behind. Now…
Read More
Dagster vs Apache Airflow: Choosing the Right Orchestrator for Modern Data Pipelines 1. Introduction Every data engineer eventually faces the…
Read More
Introduction: The 463 Zettabyte Reality Every second, millions of IoT sensors transmit temperature readings, thousands of financial transactions execute across…
Read MoreIngesting a Billion Rows: COPY, Staging Tables, and Idempotent Upserts How to build reproducible ingestion pipelines that don’t flake out…
Read More


