ML Data Engineering: Bridging the Gap Between Data and Intelligence
Machine Learning has transformed from experimental research projects to mission-critical business applications that power everything from recommendation engines and fraud detection to autonomous vehicles and medical diagnostics. However, the journey from a promising ML model in a Jupyter notebook to a production system serving millions of users requires a specialized discipline: ML Data Engineering.
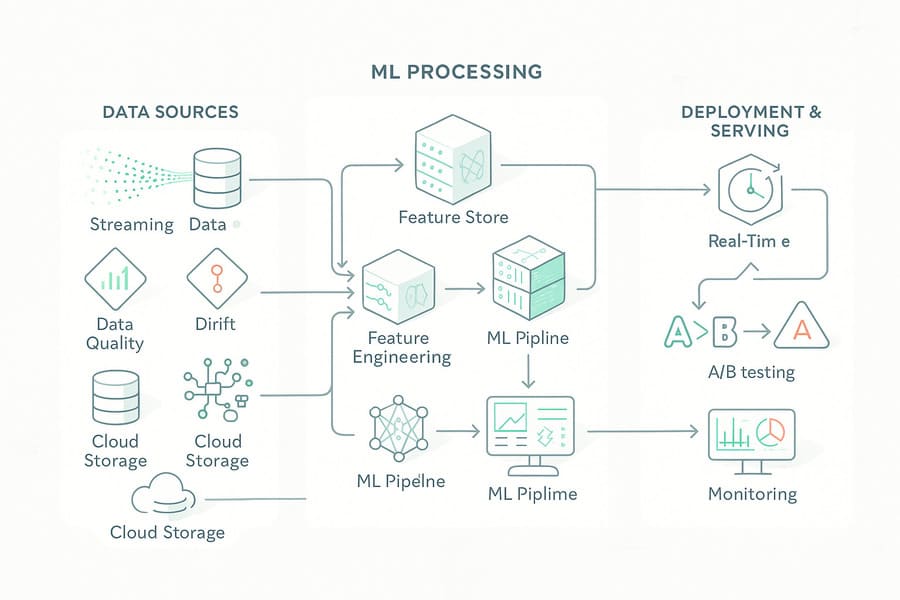
ML Data Engineering represents the convergence of traditional data engineering practices with the unique requirements of machine learning systems. It encompasses the design, implementation, and maintenance of data infrastructure specifically optimized for ML workflows, from feature engineering and model training to real-time inference and continuous learning systems.
Unlike traditional data engineering focused primarily on analytics and reporting, ML Data Engineering must address the dynamic, iterative nature of machine learning development while ensuring the reliability, scalability, and performance required for production AI systems.
The Unique Challenges of ML Data Systems
Machine learning systems introduce complexity that traditional data pipelines weren’t designed to handle. These challenges require specialized approaches and tools that form the foundation of ML Data Engineering:
Data Quality and Drift: ML models are extremely sensitive to data quality issues that might be acceptable in traditional analytics. A single corrupted feature or unexpected data distribution can cause model performance to degrade catastrophically. ML Data Engineers must implement sophisticated monitoring systems that detect not just data quality issues, but also subtle changes in data distributions that can impact model accuracy.
Feature Engineering at Scale: Converting raw data into ML-ready features often requires complex transformations, aggregations, and calculations across massive datasets. These feature pipelines must be consistent between training and inference, reproducible across different environments, and optimized for both batch and real-time processing.
Temporal Consistency: ML systems must maintain strict temporal consistency to prevent data leakage—ensuring that models only use information that would have been available at prediction time. This requires careful orchestration of data pipelines and sophisticated point-in-time feature stores.
Model Versioning and Reproducibility: Unlike traditional data outputs, ML models must be reproducible and versioned alongside their training data, feature definitions, and hyperparameters. This creates complex dependency graphs that must be managed throughout the ML lifecycle.
Real-Time Inference Requirements: Many ML applications require sub-millisecond prediction latency, demanding specialized data infrastructure that can serve features and execute models with extreme performance requirements while maintaining consistency with training data.
Core Components of ML Data Infrastructure
Modern ML Data Engineering builds upon a sophisticated stack of specialized tools and platforms designed specifically for machine learning workloads:
Feature Stores: Centralized repositories like Feast, Tecton, and AWS SageMaker Feature Store provide consistent access to features across training and inference, manage feature versioning, and enable feature sharing across teams and projects.
ML Data Pipelines: Specialized orchestration tools such as Kubeflow Pipelines, MLflow, and Vertex AI Pipelines coordinate complex ML workflows, manage dependencies between data processing, training, and deployment stages.
Model Training Infrastructure: Distributed training platforms including Ray, Horovod, and cloud-native solutions like SageMaker Training enable efficient processing of large datasets and complex models across multiple GPUs and nodes.
Real-Time Feature Serving: Low-latency serving systems built on technologies like Redis, DynamoDB, and specialized feature serving platforms ensure that online predictions have access to the same features used during training.
ML Monitoring and Observability: Platforms like Evidently AI, Arize, and Fiddler provide specialized monitoring for model performance, data drift, and prediction quality that goes far beyond traditional system monitoring.
Experiment Tracking: Tools such as Weights & Biases, Neptune, and MLflow Tracking maintain detailed records of experiments, enabling reproducibility and systematic model improvement.
The ML Data Engineering Lifecycle
ML Data Engineering operates within a continuous cycle that encompasses multiple interconnected phases, each with specific technical requirements:
Data Discovery and Ingestion: ML projects often require exploratory data analysis to identify relevant features and understand data quality issues. ML Data Engineers build flexible ingestion pipelines that can handle diverse data sources while maintaining data lineage and enabling rapid experimentation.
Feature Engineering and Selection: Raw data must be transformed into meaningful features through complex aggregations, encodings, and calculations. This process requires both statistical expertise and engineering skills to create scalable, maintainable feature pipelines.
Training Data Preparation: Creating high-quality training datasets involves sophisticated sampling strategies, data augmentation techniques, and careful handling of class imbalances and temporal dependencies. ML Data Engineers implement systems that can generate consistent, reproducible training datasets at scale.
Model Training Orchestration: Coordinating distributed training jobs, hyperparameter optimization, and cross-validation requires specialized workflow management that can handle the computational intensity and resource requirements of modern ML training.
Model Validation and Testing: Beyond traditional software testing, ML systems require validation of model performance, fairness, and robustness across different data segments and scenarios. This includes A/B testing infrastructure and shadow deployment capabilities.
Production Deployment: Serving ML models in production requires infrastructure that can handle varying traffic patterns, provide low-latency predictions, and maintain consistency between training and inference environments.
Continuous Monitoring and Retraining: Production ML systems must continuously monitor for data drift, model degradation, and concept drift, automatically triggering retraining workflows when performance degrades.
Architecture Patterns for ML Data Systems
Successful ML Data Engineering implementations typically follow established architectural patterns that address the unique requirements of machine learning workloads:
Lambda Architecture for ML: Combining batch processing for model training with real-time streaming for inference, enabling systems that can handle both historical analysis and real-time predictions with consistent feature engineering logic.
Feature Store Architecture: Centralized feature management that separates feature engineering from model development, enabling feature reuse, consistent online/offline serving, and efficient model development workflows.
MLOps Pipeline Architecture: End-to-end automation of ML workflows from data ingestion through model deployment, incorporating continuous integration and continuous deployment practices adapted for machine learning systems.
Microservices for ML: Decomposing ML systems into specialized services for feature serving, model inference, and monitoring, enabling independent scaling and deployment of different system components.
Event-Driven ML Architecture: Using event streaming platforms like Kafka to trigger ML workflows, enable real-time feature updates, and coordinate between different components of the ML system.
Data Quality and Governance in ML Systems
ML systems are uniquely vulnerable to data quality issues, requiring specialized approaches to data governance and quality assurance:
Statistical Data Validation: Beyond traditional data quality checks, ML systems require statistical validation that detects changes in data distributions, feature correlations, and other statistical properties that can impact model performance.
Feature Drift Detection: Monitoring systems that can detect when input features begin to drift from their training distributions, potentially indicating the need for model retraining or feature engineering updates.
Bias and Fairness Monitoring: Systematic evaluation of model outputs across different demographic groups and use cases to ensure fair and ethical AI deployment.
Data Lineage for ML: Tracking not just where data comes from, but how it’s transformed into features, which models use which features, and how model predictions influence business decisions.
Privacy-Preserving ML: Implementing techniques like differential privacy, federated learning, and secure multi-party computation to enable ML development while protecting sensitive data.
Performance Optimization for ML Workloads
ML Data Engineering requires specialized performance optimization techniques that address the unique computational patterns of machine learning:
Efficient Data Loading: Optimizing data loading for training workloads through techniques like data parallelism, prefetching, and efficient serialization formats like Apache Parquet and Apache Arrow.
Feature Store Optimization: Designing feature storage and retrieval systems that can serve features with microsecond latency while maintaining consistency and supporting complex feature calculations.
Model Serving Optimization: Implementing model serving infrastructure that can handle high-throughput, low-latency prediction requests through techniques like model quantization, batching, and specialized hardware acceleration.
Distributed Training Efficiency: Optimizing distributed training workflows through gradient compression, mixed-precision training, and efficient communication patterns across multiple nodes and GPUs.
Cost Optimization: Managing the high computational costs of ML workloads through spot instance usage, auto-scaling, and efficient resource allocation based on training and inference patterns.
The Business Impact of ML Data Engineering
Effective ML Data Engineering directly enables organizations to realize the full potential of their AI investments:
Faster Time-to-Market: Well-architected ML data infrastructure reduces the time from model development to production deployment from months to weeks, enabling organizations to respond quickly to business opportunities.
Improved Model Performance: Consistent, high-quality data pipelines ensure that models perform reliably in production, leading to better business outcomes and user experiences.
Scalable AI Operations: Robust ML data infrastructure enables organizations to scale from a few experimental models to hundreds of production ML systems serving millions of users.
Reduced Technical Debt: Proper ML Data Engineering practices prevent the accumulation of technical debt that often plagues organizations as they scale their ML operations.
Enhanced Collaboration: Standardized ML data platforms enable better collaboration between data scientists, ML engineers, and business teams, accelerating innovation and reducing friction.
Essential Skills for ML Data Engineers
Success in ML Data Engineering requires a unique combination of data engineering expertise and machine learning knowledge:
Deep Learning Frameworks: Proficiency with TensorFlow, PyTorch, and other ML frameworks, including understanding of distributed training, model optimization, and deployment patterns.
Feature Engineering Expertise: Advanced knowledge of statistical methods, data transformations, and domain-specific feature engineering techniques across different types of data (text, images, time series, etc.).
MLOps Tools and Practices: Hands-on experience with MLOps platforms, experiment tracking, model versioning, and automated ML pipeline development.
Streaming and Real-Time Systems: Understanding of stream processing frameworks like Apache Kafka, Apache Flink, and cloud streaming services for real-time ML applications.
Statistical Understanding: Solid foundation in statistics and probability theory to understand model behavior, data distributions, and validation methodologies.
Cloud ML Services: Expertise with cloud-native ML services like AWS SageMaker, Google Vertex AI, and Azure ML, including their integration with broader data ecosystems.
Emerging Trends in ML Data Engineering
The field of ML Data Engineering continues to evolve rapidly, driven by advances in both machine learning and data infrastructure:
Real-Time ML Everywhere: The demand for real-time predictions is expanding beyond traditional use cases, requiring ML data infrastructure that can support sub-millisecond inference at massive scale.
Automated Feature Engineering: AutoML platforms are beginning to automate feature engineering tasks, requiring ML Data Engineers to build infrastructure that can support automated experimentation and optimization.
Edge ML Deployment: The move toward edge computing is creating new requirements for ML data infrastructure that can support model deployment and updates across distributed edge devices.
Federated Learning Infrastructure: Privacy-preserving ML techniques like federated learning require specialized data infrastructure that can coordinate training across multiple organizations while maintaining data privacy.
LLM and Foundation Model Integration: The rise of large language models and foundation models is creating new infrastructure requirements for fine-tuning, prompt engineering, and hybrid model architectures.
Building Your ML Data Engineering Capability
Organizations looking to build or enhance their ML Data Engineering capabilities should focus on several key areas:
Start with Use Case Definition: Clearly define the business problems you’re trying to solve with ML and the specific requirements for data, performance, and scale.
Invest in Foundational Infrastructure: Build robust data pipelines, feature stores, and model serving infrastructure before scaling to multiple ML use cases.
Establish MLOps Practices: Implement version control, automated testing, and continuous deployment practices specifically adapted for machine learning workflows.
Focus on Data Quality: Invest heavily in data quality monitoring, validation, and governance systems that can detect ML-specific issues like data drift and bias.
Build Cross-Functional Teams: Create teams that combine data engineering expertise with machine learning knowledge and domain expertise.
Key Takeaways
ML Data Engineering represents a critical discipline at the intersection of data engineering and machine learning, requiring specialized skills, tools, and practices to succeed. The field addresses unique challenges around data quality, feature engineering, model serving, and continuous learning that traditional data engineering approaches cannot adequately handle.
Success in ML Data Engineering requires understanding both the technical complexity of machine learning systems and the operational requirements of production data infrastructure. Organizations that invest in robust ML data engineering capabilities will be better positioned to realize the full potential of their AI investments while avoiding the common pitfalls that prevent ML projects from reaching production.
The field continues to evolve rapidly, with new tools, techniques, and best practices emerging regularly. However, the fundamental principles remain consistent: build reliable, scalable systems that enable consistent data access across the ML lifecycle, implement comprehensive monitoring and quality assurance, and maintain the flexibility to adapt to changing business requirements and technological advances.
As you explore the comprehensive ecosystem of ML Data Engineering tools and platforms outlined below, consider how each component contributes to the end-to-end ML lifecycle and how they integrate to create powerful, production-ready machine learning systems that drive real business value.



