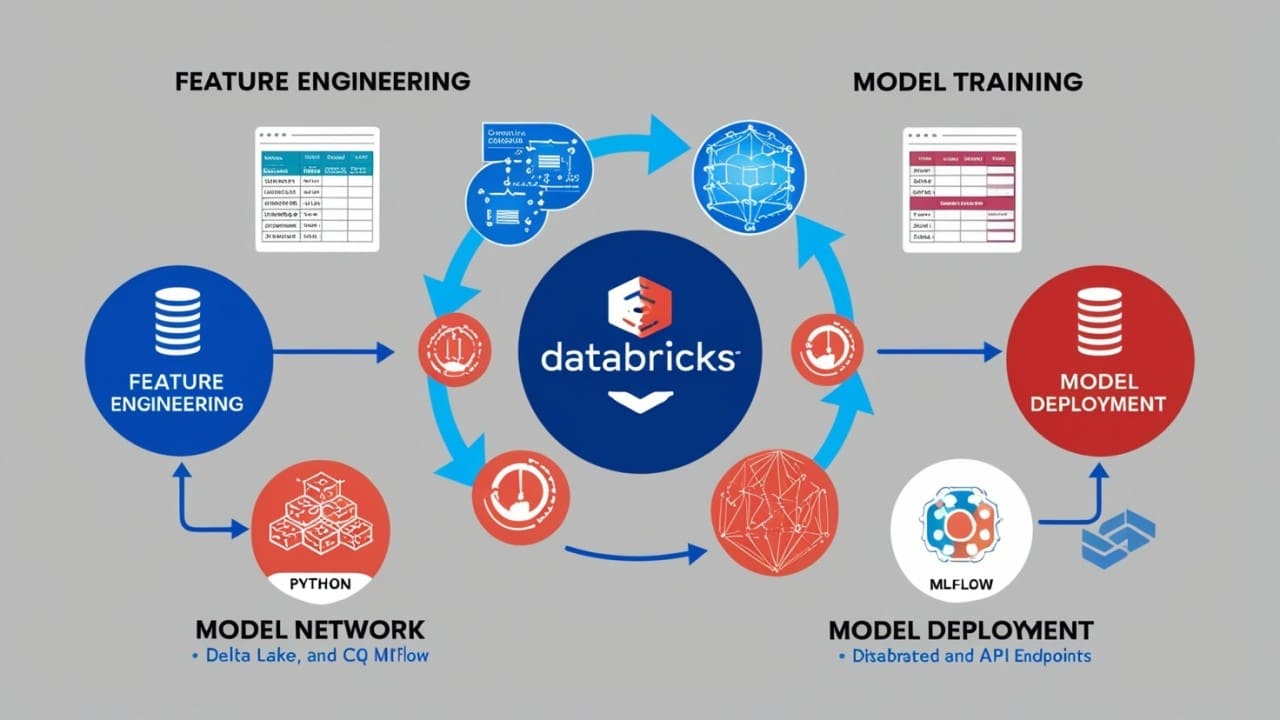
Databricks for Machine Learning: A Comprehensive Guide
In today’s data-driven world, machine learning (ML) is a critical tool for gaining insights and driving innovation. But to make ML effective, you need a powerful, scalable, and collaborative platform—and Databricks is exactly that. Built on Apache Spark, Databricks simplifies the end-to-end ML lifecycle, from data preparation to model deployment, all while ensuring scalability and performance.
This article explores how Databricks empowers machine learning workflows, focusing on feature engineering, model training, and model deployment.
1. Why Choose Databricks for Machine Learning?
Databricks offers a unified platform that integrates data engineering, data science, and ML workflows, making it an ideal choice for teams working on large-scale projects. Key advantages include:
- Scalability: Databricks leverages Apache Spark’s distributed computing capabilities, enabling seamless handling of massive datasets.
- Collaborative Environment: Databricks notebooks allow real-time collaboration among data engineers, data scientists, and analysts.
- Integrated ML Frameworks: Databricks supports popular ML libraries like TensorFlow, PyTorch, and Scikit-learn.
- Lakehouse Architecture: Combines the scalability of data lakes with the performance of data warehouses, ensuring high-speed data access.
2. Feature Engineering in Databricks
Feature engineering is the foundation of successful machine learning models, and Databricks provides powerful tools to simplify this process.
Key Capabilities:
- Apache Spark for Data Processing: Use Spark’s distributed computing power to clean, aggregate, and transform large datasets efficiently.
- Delta Lake: Enables ACID transactions, ensuring data integrity during complex transformations.
- SQL and Python Support: Write feature engineering workflows using SQL, Python, or a combination of both.
Examples:
- Customer Segmentation:
from pyspark.sql import functions as F
df = spark.read.format("delta").load("/path/to/delta_table")
df = df.groupBy("customer_id").agg(
F.avg("purchase_amount").alias("avg_purchase"),
F.max("purchase_date").alias("last_purchase_date")
)- Fraud Detection: Use time-series aggregations to detect anomalous transaction patterns.
SELECT customer_id,
SUM(amount) AS total_spent,
COUNT(transaction_id) AS num_transactions
FROM transactions
WHERE transaction_date > current_date - INTERVAL 30 DAYS
GROUP BY customer_id;Data Versioning for Reproducibility:
Delta Lake’s time travel feature allows you to version datasets, ensuring consistent and reproducible feature engineering pipelines.
3. Model Training with Databricks
Databricks simplifies model training by integrating seamlessly with ML frameworks and providing powerful tools for distributed training.
Key Features:
- MLflow Integration: Manage experiments, track metrics, and version models directly within Databricks.
- GPU Support: Accelerate training for deep learning models using GPU-enabled clusters.
- Hyperparameter Tuning: Leverage libraries like Hyperopt or Optuna to automate hyperparameter optimization.
Example Workflow:
1. Load Data:
train_data = spark.read.format("delta").load("/path/to/train_data")2.Train the Model:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
train_data["features"], train_data["labels"], test_size=0.2
)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)3.Track the Experiment:
import mlflow.sklearn
with mlflow.start_run():
mlflow.sklearn.log_model(model, "random_forest_model")
mlflow.log_metric("accuracy", model.score(X_test, y_test))Examples:
- Retail Use Case: Train a model to predict customer lifetime value using historical purchase data.
- Healthcare Use Case: Develop a model to predict patient health outcomes based on clinical records.
4. Model Deployment with Databricks
Databricks simplifies the deployment of ML models, enabling real-time or batch inference at scale.
Deployment Options:
- Real-Time Serving: Deploy models as REST APIs using MLflow model serving.
- Batch Inference: Perform batch scoring on large datasets using Spark.
- Databricks Jobs: Automate model inference workflows with scheduled jobs.
Example Deployment Workflow:
1.Serve the Model:
mlflow.sklearn.log_model(model, "model")
mlflow.models.serve("model", host="0.0.0.0", port=5000)2.Batch Inference:
predictions = model.transform(spark.read.format("delta").load("/path/to/data"))
predictions.write.format("delta").save("/path/to/predictions")Examples:
- E-Commerce: Use real-time recommendation models to personalize product suggestions.
- Finance: Deploy fraud detection models to flag suspicious transactions in real time.
5. Best Practices for ML Workflows in Databricks
To make the most of Databricks for ML, follow these best practices:
- Leverage Delta Lake: Ensure data reliability and consistency for feature engineering and model inference.
- Automate Workflows: Use Databricks Jobs or Airflow to schedule and manage pipelines.
- Optimize Cluster Configurations: Use autoscaling clusters and spot instances to reduce costs.
- Collaborate Effectively: Share notebooks and dashboards to improve team collaboration.
Conclusion
Databricks is a powerful platform for managing the end-to-end machine learning lifecycle. From efficient feature engineering to scalable model training and seamless deployment, Databricks simplifies the complexity of ML workflows.
Whether you’re building recommendation engines, fraud detection models, or predictive analytics systems, Databricks provides the tools and scalability to succeed.
How are you using Databricks for your machine learning projects? Share your experiences and tips in the comments below!







Leave a Reply