Star Schema: The Cornerstone of Data Warehouse Architecture
In the realm of data warehouse design, few architectural patterns have proven as enduring and effective as the Star Schema. This elegantly simple yet powerful approach has become the foundation of countless successful business intelligence implementations, empowering organizations to transform complex data into actionable insights with remarkable efficiency.
What is a Star Schema?
A Star Schema is a specialized database design pattern optimized for data warehousing and analytical processing. Named for its distinctive star-like appearance in entity-relationship diagrams, this schema consists of a central fact table connected to multiple dimension tables, forming a structure that resembles a star with rays extending outward.
This architectural pattern was popularized by Ralph Kimball as part of his dimensional modeling approach to data warehousing. Its primary purpose is to organize data in a way that optimizes query performance while maintaining a structure that business users can intuitively understand.
Anatomy of a Star Schema
The Fact Table: The Central Hub
At the core of any Star Schema lies the fact table—the central repository for quantitative business metrics. The fact table contains:
- Foreign keys that connect to dimension tables
- Numerical measures (facts) such as sales amount, quantity sold, or profit
- Typically high volume with millions or billions of rows
- Granular data points representing specific business events
The fact table focuses exclusively on measurable business events or transactions. It rarely contains descriptive attributes, which are instead relegated to dimension tables.
Dimension Tables: The Descriptive Context
Surrounding the fact table are dimension tables, which provide the descriptive context for the numerical measures. Dimension tables typically contain:
- Primary keys that connect to the fact table
- Descriptive attributes that provide context for analysis
- Hierarchical relationships (e.g., products within categories within departments)
- Relatively smaller size compared to fact tables
- Denormalized structure with redundant data
Common dimensions include time, geography, product, customer, and employee—though the specific dimensions vary based on business requirements.
The Power of Star Schema: Key Advantages
1. Query Performance Optimization
The Star Schema’s structure dramatically simplifies complex analytical queries. By denormalizing dimension tables, it reduces the number of joins required to answer business questions, resulting in:
- Faster query execution
- Simplified SQL statements
- Reduced I/O operations
- Better utilization of database caching
For OLAP workloads, where complex aggregations across multiple dimensions are common, this performance advantage becomes particularly significant.
2. Business User Accessibility
The intuitive structure of the Star Schema makes it remarkably accessible to business users, even those with limited technical expertise:
- Dimensions align with natural business entities
- Attribute relationships follow intuitive hierarchies
- Query paths are straightforward and predictable
- Column names can utilize business terminology
This accessibility reduces the translation burden between technical and business teams, enabling more direct interaction with the data.
3. Predictable Query Performance
The consistent structure of Star Schemas leads to more predictable query performance:
- Join patterns remain consistent across different analyses
- Query optimization techniques can be standardized
- Indexing strategies are well-established
- Performance tuning becomes more systematic
This predictability becomes increasingly valuable as data volumes grow and performance requirements become more stringent.
4. Extensibility
Well-designed Star Schemas can elegantly accommodate business changes:
- New dimensions can be added without disrupting existing functionality
- Additional attributes can be incorporated into dimension tables
- New metrics can be added to fact tables
- Historical changes can be managed through SCD techniques
This extensibility ensures that the data model can evolve alongside changing business requirements.
Practical Implementation: Building an Effective Star Schema
Identifying Fact Tables
The first step in designing a Star Schema is identifying the business processes to be modeled. Each core business process typically corresponds to a fact table, such as:
- Sales transactions
- Inventory movements
- Customer service interactions
- Manufacturing operations
- Financial transactions
The granularity of these fact tables should be carefully considered—too granular, and the table becomes unwieldy; too aggregated, and analytical flexibility is lost.
Defining Dimensions
Once fact tables are identified, the next step is defining the dimensions that provide context. Effective dimension design involves:
- Identifying descriptive attributes relevant to analysis
- Organizing attributes into hierarchies (e.g., day → month → quarter → year)
- Establishing naming conventions that business users understand
- Determining strategies for handling changes (Slowly Changing Dimensions)
- Considering reusability across multiple fact tables (conformed dimensions)
Well-designed dimensions dramatically enhance the analytical capabilities of the Star Schema.
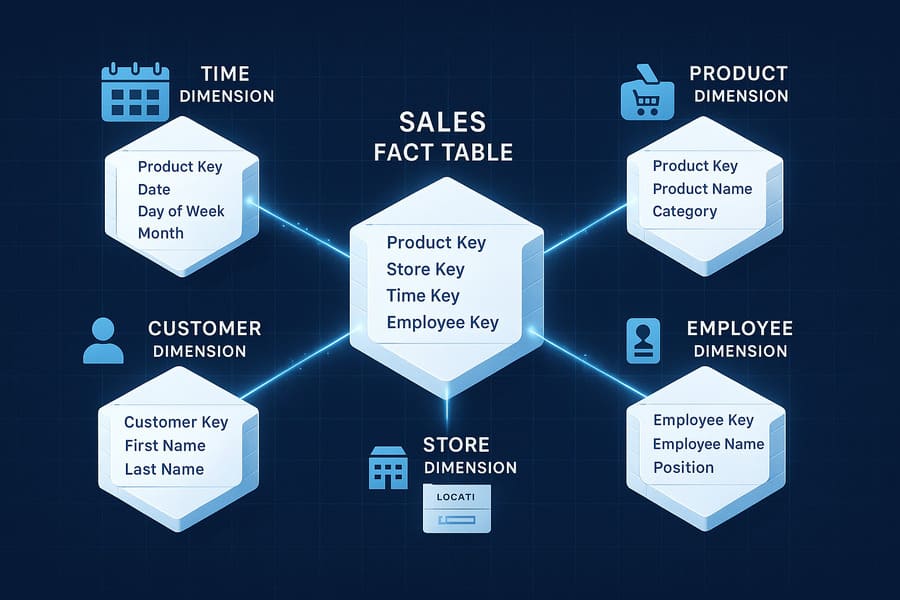
Case Study: Retail Sales Analysis
Consider a retail sales analysis system implemented with a Star Schema:
The central Sales Fact table contains:
- Transaction ID
- Date Key (foreign key to Date dimension)
- Product Key (foreign key to Product dimension)
- Store Key (foreign key to Store dimension)
- Customer Key (foreign key to Customer dimension)
- Employee Key (foreign key to Employee dimension)
- Quantity Sold (measure)
- Unit Price (measure)
- Discount Amount (measure)
- Sales Amount (measure)
- Cost Amount (measure)
- Profit Amount (measure)
Surrounding dimension tables provide rich context:
- Date Dimension: Calendar date, day of week, month, quarter, year, season, holiday flag
- Product Dimension: Product ID, name, description, brand, category, department, size, color, weight
- Store Dimension: Store ID, name, format, address, city, state, country, opening date, square footage
- Customer Dimension: Customer ID, name, address, city, state, country, segment, acquisition date
- Employee Dimension: Employee ID, name, position, department, hire date, manager ID
This structure enables powerful analyses like:
- Sales performance by product category across different store formats
- Seasonal sales patterns for specific customer segments
- Employee sales performance by department and time period
- Profitability analysis across multiple dimensions
Star Schema vs. Snowflake Schema: When to Choose Each
While the Star Schema denormalizes dimension tables for performance, the Snowflake Schema normalizes them to reduce redundancy. The choice between these approaches involves several considerations:
Choose Star Schema when:
- Query performance is paramount
- Storage costs are not a primary concern
- ETL processes can manage denormalized updates efficiently
- Business users require direct access to the model
- Query patterns involve numerous dimensions simultaneously
Choose Snowflake Schema when:
- Storage efficiency is critical
- Dimension tables are extremely large
- Dimension hierarchies are complex and frequently changing
- Data quality and consistency are significant concerns
- Normalization aligns with source system structures
In practice, many implementations use a hybrid approach, normalizing certain dimensions while denormalizing others based on specific requirements.
Technical Optimizations for Star Schema
Modern data warehousing environments offer numerous techniques to enhance Star Schema performance:
Indexing Strategies
- Clustered indexes on fact table foreign keys
- Bitmap indexes for low-cardinality dimension attributes
- Covering indexes for common query patterns
- Partitioning fact tables by date or other dimensions
Materialized Views
- Pre-aggregated summary tables for common grouping levels
- Incremental refresh strategies to maintain currency
- Query rewrite capabilities to leverage aggregates automatically
Columnar Storage
- Column-oriented storage for improved compression and I/O
- Predicate pushdown for efficient filtering
- Late materialization to process only required columns
In-Memory Processing
- Keeping frequently accessed dimension tables in memory
- Memory-optimized fact table aggregations
- Vectorized processing for efficient computation
Common Challenges and Solutions
Challenge: Handling Multi-Valued Dimensions
When a fact has multiple values for a single dimension (e.g., a product with multiple categories), several approaches can be used:
- Bridge tables connecting facts to multiple dimension values
- Junk dimensions combining multiple attributes into single dimensions
- Array or JSON columns in modern data warehouses
- Factless fact tables to model many-to-many relationships
Challenge: Slowly Changing Dimensions
Business realities change over time, requiring strategies to track historical dimension attributes:
- Type 1 SCD: Overwrite old values (no history)
- Type 2 SCD: Add new rows with effective dates
- Type 3 SCD: Add columns for previous values
- Type 6 SCD: Combine multiple approaches
Challenge: Handling Sparse Facts
When fact tables contain metrics applicable to only some dimension combinations:
- Separate fact tables for different measure groups
- Null values with appropriate handling in queries
- Sparse matrix storage techniques in modern platforms
- Factless fact tables for event relationships
Future of Star Schema in Modern Data Architectures
While the Star Schema emerged in traditional relational database environments, its influence extends into modern data architectures:
In Cloud Data Warehouses
- Massive parallelism enhances Star Schema performance
- Dynamic scaling accommodates growing fact tables
- Separation of storage and compute enables cost-efficient operations
- Semi-structured data support extends dimensional concepts
In Data Lakes
- Schema-on-read approaches influenced by dimensional concepts
- Delta Lake and similar technologies bring ACID properties to lake storage
- Medallion architectures incorporate dimensional modeling at certain layers
In Big Data Platforms
- Dimensional modeling principles adapted for distributed storage
- Denormalization advantages align with distributed processing models
- Star-join optimization in SQL-on-Hadoop engines
Best Practices for Star Schema Implementation
Design Phase
- Start with business questions, not available data
- Define consistent granularity for each fact table
- Create conformed dimensions to enable cross-process analysis
- Establish naming conventions that bridge technical and business terminology
- Document business rules for calculated measures
Implementation Phase
- Begin with representative sample data to validate design
- Implement incrementally by business process
- Develop automated tests for data consistency
- Create reference queries for common analytical patterns
- Optimize for predominant query patterns
Maintenance Phase
- Monitor query performance patterns to identify optimization opportunities
- Document dimensional changes thoroughly
- Establish governance processes for dimensional additions
- Create view layers to insulate users from structural changes
- Regularly review for changing business requirements
Conclusion: The Enduring Value of Star Schema
Despite the rapid evolution of data technologies, the Star Schema remains remarkably relevant. Its fundamental insight—organizing data around business metrics and their descriptive context—transcends specific technologies and continues to inform effective data modeling across diverse environments.
The Star Schema’s balance of analytical power, query performance, and business accessibility ensures it will remain a cornerstone of data warehouse architecture for years to come. By understanding its principles and applying them thoughtfully, data engineers can create analytical environments that truly empower business decision-making.
For organizations embarking on data warehousing initiatives, the Star Schema provides not just a technical pattern but a conceptual framework that aligns technical implementation with business thinking—perhaps its most enduring contribution to the field of data engineering.
Keywords: star schema, data warehouse architecture, dimensional modeling, fact table, dimension table, OLAP, Ralph Kimball, query optimization, business intelligence, data mart, denormalization, conformed dimensions, data modeling, ETL, analytical database design
Hashtags: #StarSchema #DataWarehouse #DimensionalModeling #DataEngineering #BusinessIntelligence #DataArchitecture #FactTable #DimensionTable #DataModeling #KimballMethodology #Analytics #OLAP #DataMart #ETL #DataStrategy



