Data Warehouse Design: Architectures for Effective Data Management
Data Governance and Management (DGaM)
Data Warehouse Architectures (DWA)
Enterprise Data Warehouse vs. Data Marts
Logical vs. Physical Data Models
Galaxy Schema (Fact Constellation)
Kimball (Dimensional) Approach
Dimensional Modeling Techniques (DMT)
Fact Table Design Patterns (FTDP)
Accumulating Snapshot Fact Tables
Modern Data Warehouse Concepts (MDWC)
In the complex ecosystem of enterprise data management, data warehouse design stands as the architectural foundation that determines how efficiently an organization can transform raw data into actionable insights. The strategic decisions made during the design phase directly impact query performance, data integration complexity, and ultimately, the business value derived from analytics.
Data Warehouse Schemas: The Blueprint of Your Data Architecture
Data warehouse schemas define the structural relationship between fact and dimension tables—essentially providing the blueprint for how your analytical data will be organized. Each schema type offers distinct advantages that align with specific use cases and organizational requirements.
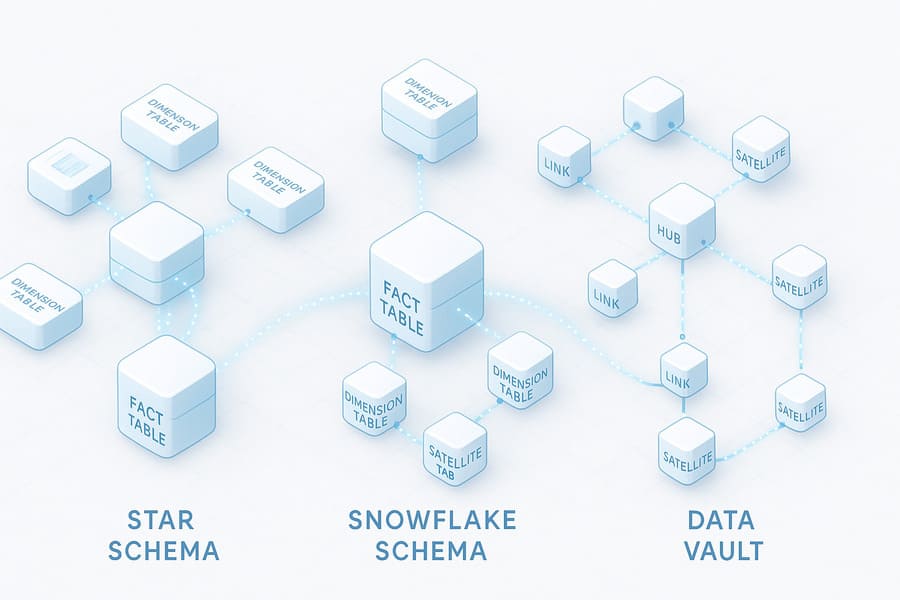
Star Schema: Simplicity Meets Performance
The Star Schema represents one of the most straightforward and widely implemented data warehouse designs. At its core lies a central fact table surrounded by dimension tables, creating a star-like pattern in entity-relationship diagrams.
Key Characteristics:
- A single, central fact table containing business metrics
- Dimension tables connecting directly to the fact table (not to each other)
- Denormalized dimension tables with redundant data
- Simple, intuitive structure that business users can easily understand
Ideal For:
- OLAP (Online Analytical Processing) operations requiring rapid query responses
- BI tools and dashboards needing consistent performance
- Organizations prioritizing query speed over storage efficiency
The Star Schema’s simplicity translates to exceptional query performance, making it the go-to choice when analytical speed takes precedence over storage considerations.
Snowflake Schema: When Normalization Matters
The Snowflake Schema extends the Star Schema concept by introducing normalization to dimension tables. This approach “snowflakes” the schema design by breaking dimension tables into multiple related tables.
Key Characteristics:
- Normalized dimension tables divided into multiple related tables
- Reduced data redundancy compared to Star Schema
- More complex join operations required for queries
- Better storage efficiency with minimal data duplication
Ideal For:
- Environments where storage costs are a significant concern
- Data warehouses with complex dimensional hierarchies
- Organizations with strict data quality and integrity requirements
While the Snowflake Schema optimizes storage usage, it introduces additional joins that can impact query performance. This trade-off must be carefully weighed against business requirements.
Galaxy Schema (Fact Constellation): Managing Multiple Business Processes
The Galaxy Schema (also known as Fact Constellation) extends beyond single-focus designs by incorporating multiple fact tables that share dimension tables, creating a constellation-like structure.
Key Characteristics:
- Multiple fact tables sharing common dimension tables
- Support for analyzing distinct but related business processes
- Balanced approach for enterprises with diverse analytical needs
- More complex design requiring thoughtful implementation
Ideal For:
- Enterprise data warehouses supporting multiple business domains
- Organizations needing to analyze related business processes
- Environments requiring flexible, expandable data models
The Galaxy Schema provides a middle ground between isolated data marts and monolithic warehouses, offering domain separation while maintaining dimensional consistency.
Data Vault: Adaptability for the Long Term
The Data Vault represents a modern approach to data warehouse modeling that emphasizes long-term adaptability, auditability, and resilience to change.
Key Characteristics:
- Hub tables containing business keys
- Link tables representing relationships between hubs
- Satellite tables storing descriptive attributes and historical records
- Clear separation of concerns between structure and content
Ideal For:
- Organizations experiencing frequent business changes
- Environments requiring complete historical auditability
- Enterprise data warehouses serving as the system of record
- Projects needing to integrate diverse data sources over time
Data Vault excels in complex enterprise environments where change is constant and historical tracking is paramount. Its modular design allows for incremental loading and parallel processing.
Inmon (Normalized) Approach: Enterprise-First Architecture
Bill Inmon’s approach to data warehousing advocates for an enterprise-wide, normalized design that serves as the foundation for departmental data marts.
Key Characteristics:
- Highly normalized (3NF) enterprise data warehouse
- Top-down approach starting with enterprise-wide modeling
- Subject-oriented, integrated, time-variant, and non-volatile
- Departmental data marts derived from the central warehouse
Ideal For:
- Organizations requiring a single version of truth across all departments
- Enterprises with complex data relationships requiring normalization
- Environments where data consistency takes precedence over query performance
The Inmon approach emphasizes data integrity and integration at the enterprise level, with performance optimization occurring in the derived data marts.
Kimball (Dimensional) Approach: Business-Driven Design
Ralph Kimball’s dimensional modeling approach takes a bottom-up perspective, focusing on business processes and dimensional consistency across the enterprise.
Key Characteristics:
- Dimensional model using star or snowflake schemas
- Bottom-up approach starting with specific business processes
- Conformed dimensions shared across multiple fact tables
- Bus architecture enabling incremental implementation
Ideal For:
- Organizations prioritizing business user accessibility
- Projects requiring incremental delivery of value
- Environments where query performance is a primary concern
- Business intelligence and analytics-focused implementations
The Kimball methodology prioritizes usability and performance from the business perspective, making it particularly well-suited for analytics-focused data warehouses.
Slowly Changing Dimensions (SCD): Preserving the History of Change
In data warehousing, dimensions aren’t static—they evolve over time. Slowly Changing Dimensions (SCDs) provide methodologies for tracking these changes while maintaining historical context for accurate analytics.
Type 0: Retain Original
The simplest approach to handling dimension changes is to simply ignore them, retaining the original values regardless of real-world changes.
Key Characteristics:
- Original attribute values never change
- No tracking of historical changes
- Simplest implementation requiring minimal storage
- Appropriate for attributes that should remain constant
Ideal For:
- Immutable attributes (birth date, original customer ID)
- Reference data that should remain consistent for analysis
- Scenarios where historical accuracy of certain attributes isn’t relevant
Type 0 SCDs provide stability for attributes that should remain consistent throughout analysis, regardless of real-world changes.
Type 1: Overwrite
Type 1 SCDs take the straightforward approach of simply overwriting old values with new ones, maintaining only the current state.
Key Characteristics:
- Current values overwrite previous values
- No historical tracking of changes
- Simplest implementation with standard update statements
- Minimal storage requirements
Ideal For:
- Correction of erroneous data
- Attributes where historical values aren’t analytically relevant
- Scenarios where only the current state matters
While Type 1 SCDs sacrifice historical accuracy, they provide a clean, storage-efficient approach for attributes where historical tracking adds no analytical value.
Type 2: Add New Row
The most common SCD approach for preserving history, Type 2 creates a new dimension record when attributes change, allowing for point-in-time historical analysis.
Key Characteristics:
- New row added when tracked attributes change
- Effective date ranges and current record flags
- Complete historical tracking of changes
- Increased storage requirements proportional to change frequency
Ideal For:
- Critical business dimensions requiring historical accuracy
- Regulatory environments requiring complete audit trails
- Analysis requiring point-in-time dimensional context
- Attributes frequently used in trend analysis
Type 2 SCDs excel in scenarios requiring complete historical accuracy, enabling precise point-in-time reporting and trend analysis.
Type 3: Add New Attributes
Type 3 SCDs preserve limited history by adding new columns to store previous values alongside current ones.
Key Characteristics:
- Previous value columns alongside current value
- Limited historical tracking (typically only one previous state)
- Moderate implementation complexity
- Controlled storage growth independent of change frequency
Ideal For:
- Attributes requiring comparison between current and previous states
- Scenarios where only the most recent previous value matters
- Dimensions with predictable, infrequent changes
- Analysis focused on “before and after” comparisons
Type 3 provides a middle ground between Type 1 and Type 2, offering limited historical context without the storage implications of complete history tracking.
Type 4: History Table
Type 4 extends the dimensional model by creating separate history tables to track changes, keeping the current dimension table lean and focused on current values.
Key Characteristics:
- Separate history table containing all historical records
- Current dimension table containing only active records
- Optimized query performance for current-state analysis
- Clear separation between current and historical data
Ideal For:
- High-volume dimensions with frequent changes
- Environments with disparate performance requirements for current vs. historical analysis
- Systems requiring optimized storage and query performance
- Implementations where most queries focus on current state
Type 4 SCDs provide architectural separation between current and historical states, optimizing for the most common query patterns while preserving full history.
Type 6: Hybrid Approach (“Combine 1+2+3”)
Type 6 SCDs (sometimes called “hybrid” or “combined”) incorporate techniques from Types 1, 2, and 3 to provide comprehensive change tracking with optimized query performance.
Key Characteristics:
- New rows for history tracking (Type 2)
- Current value flags or columns for quick current-state access (Type 1)
- Previous value columns for specific attributes (Type 3)
- Comprehensive solution addressing multiple requirements
Ideal For:
- Complex analytical environments with diverse query patterns
- Systems requiring both historical accuracy and query performance
- Enterprise data warehouses serving multiple analytical use cases
- Dimensions where different attributes have different tracking requirements
Type 6 represents a pragmatic approach that balances competing requirements, though at the cost of increased design and implementation complexity.
Type 7: Bi-temporal
Type 7 SCDs implement bi-temporal data modeling, tracking both business effective time and system record time to provide comprehensive auditing and historical analysis capabilities.
Key Characteristics:
- Dual time tracking: business effective dates and system record dates
- Ability to reconstruct the database state at any point in time
- Support for retroactive changes and corrections
- Comprehensive audit capabilities for regulatory compliance
Ideal For:
- Financial systems requiring comprehensive audit trails
- Regulatory environments with strict compliance requirements
- Scenarios requiring the ability to reconstruct historical understanding
- Applications where “as of” reporting is critical
Bi-temporal modeling represents the most comprehensive approach to tracking dimensional changes, though with corresponding complexity in both implementation and query patterns.
Strategic Implementation Considerations
When implementing data warehouse schemas and SCD strategies, consider the following:
- Start with the business requirements, not the technical architecture. The most elegant schema is worthless if it doesn’t support the analytical needs of the organization.
- Consider the full data lifecycle, from initial loading to historical archiving. Today’s design decisions will impact operations years into the future.
- Balance performance against maintainability. Highly optimized designs often sacrifice flexibility and comprehensibility.
- Implement consistent dimensional modeling across the enterprise to enable integrated analytics.
- Document your design choices thoroughly, including the reasoning behind schema and SCD selections for different entities.
By thoughtfully applying these schema and SCD patterns based on specific business requirements rather than technical preferences, organizations can develop data warehouse architectures that deliver sustained value through changing business conditions and evolving analytical needs.
Conclusion
Data warehouse design isn’t merely a technical exercise—it’s a strategic business decision that shapes an organization’s analytical capabilities for years to come. By understanding the strengths and limitations of different schema types and SCD methodologies, data engineers and architects can create data environments that balance performance, flexibility, and historical accuracy to deliver maximum business value.
The most successful implementations don’t rigidly adhere to a single approach but thoughtfully apply the right patterns to the right problems, creating a cohesive architecture that evolves alongside the organization’s analytical maturity.
Keywords: data warehouse design, star schema, snowflake schema, galaxy schema, fact constellation, data vault, Inmon approach, Kimball approach, slowly changing dimensions, SCD Type 0, SCD Type 1, SCD Type 2, SCD Type 3, SCD Type 4, SCD Type 6, SCD Type 7, bi-temporal modeling, dimensional modeling, data warehouse architecture, data modeling strategies
Hashtags: #DataWarehouseDesign #DataModeling #StarSchema #SnowflakeSchema #GalaxySchema #DataVault #InmonVsKimball #SlowlyChangingDimensions #SCD #DataEngineering #BusinessIntelligence #DataArchitecture #BI #Analytics #DimensionalModeling



