Skip to content
AI
Analytics
AWS
ClickHouse
Data
Databricks
Data & ML Engineering
Home
AI
Analytics
AWS
ClickHouse
Data
Databricks
DataLake
DevOps
Data
Monitoring 101 for Data Engineers
Oracle
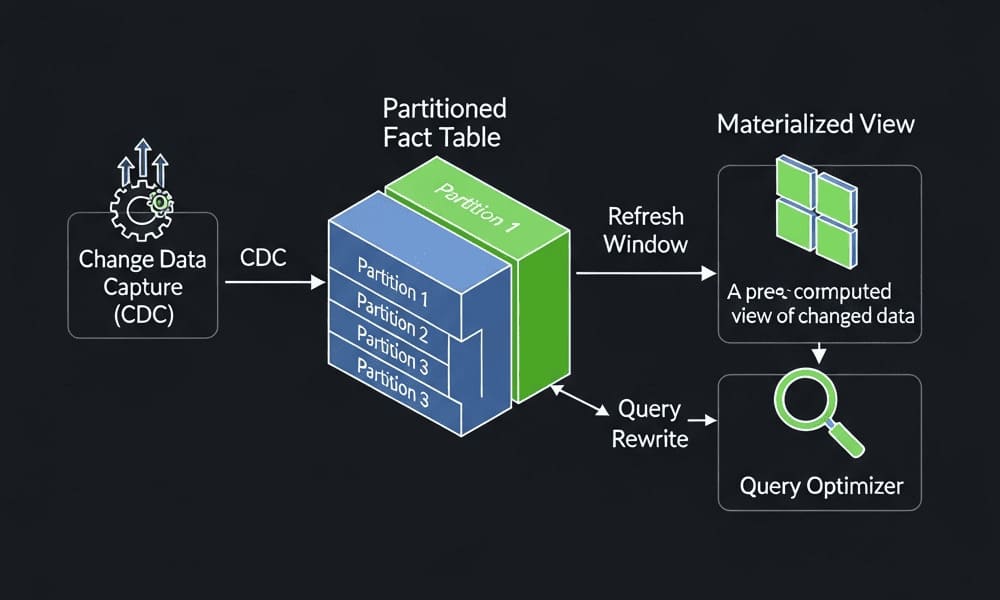
Materialized Views in the Real World
NoSQL
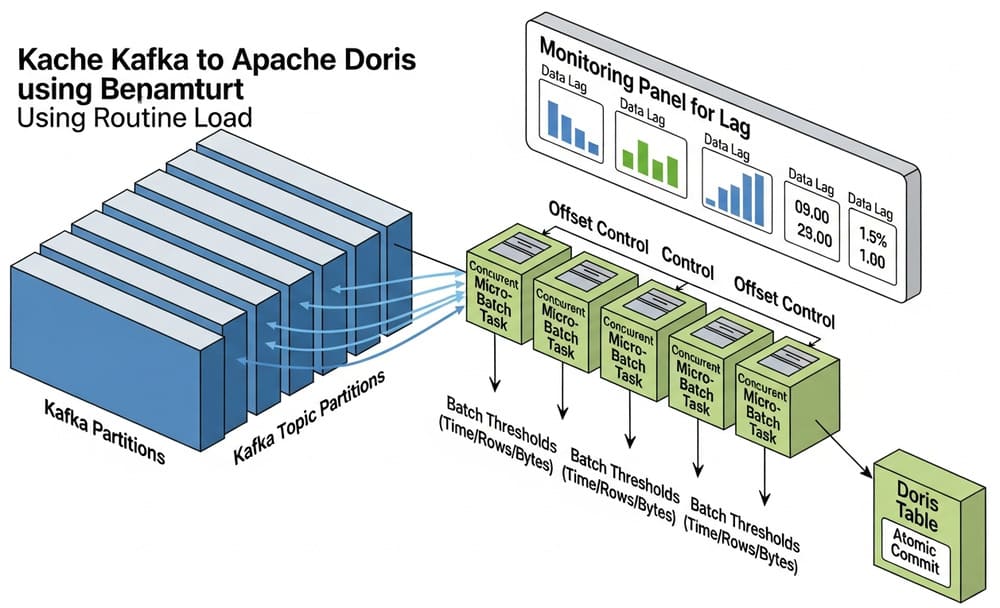
Kafka Ingestion with Apache Doris Routine Load
Data
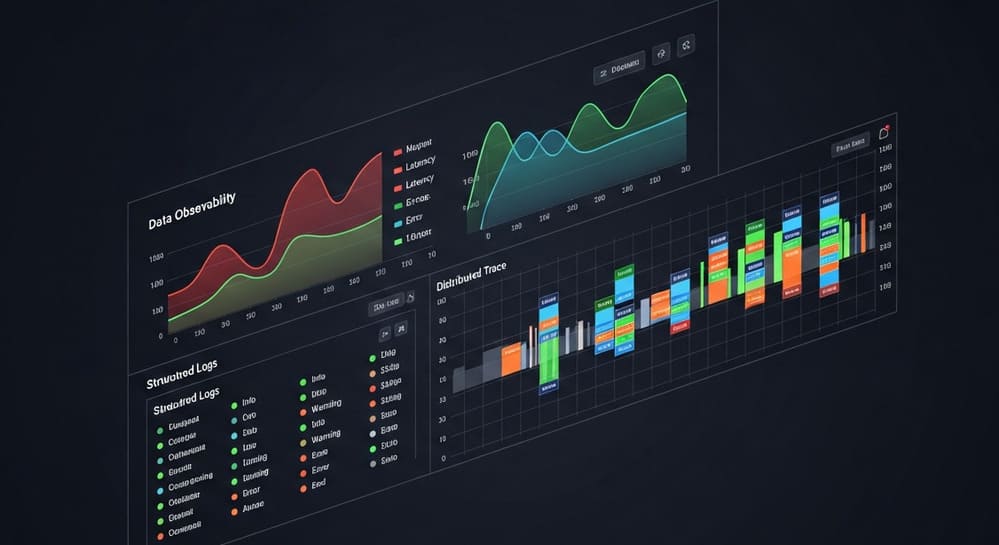
Structured Logging 101
NoSQL
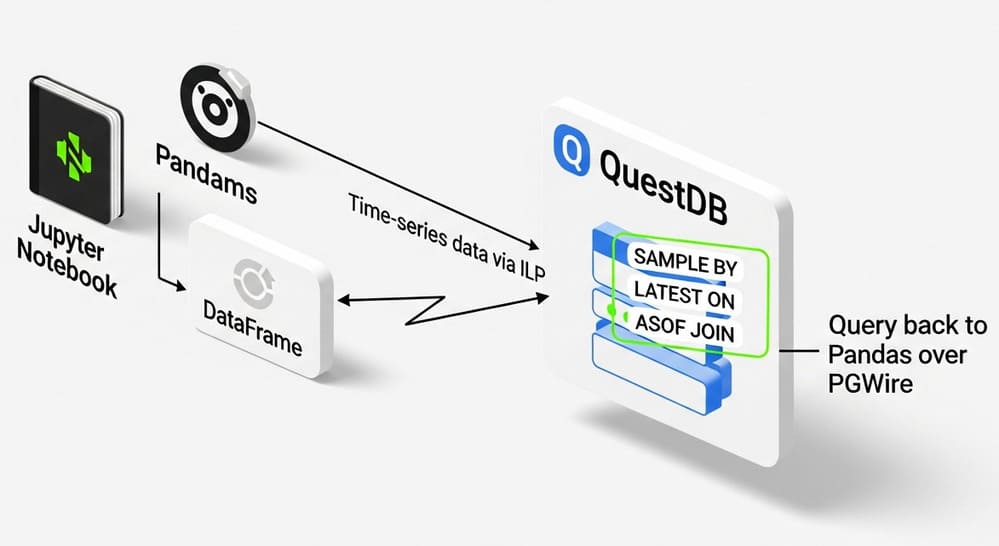
Pandas → QuestDB
Data
Monitoring 101 for Data Engineers
Alex
|
Nov 25, 2025
Oracle
Materialized Views in the Real World
Alex
|
Nov 21, 2025
NoSQL
Kafka Ingestion with Apache Doris Routine Load
Alex
|
Nov 20, 2025
Data
Structured Logging 101
Alex
|
Nov 18, 2025
NoSQL
Pandas → QuestDB
Alex
|
Nov 13, 2025
Data
Snowflake
Snowflake Workspaces
Alex
|
Nov 11, 2025
Data
Python
5 Python Design Patterns
Alex
|
Nov 9, 2025
Data
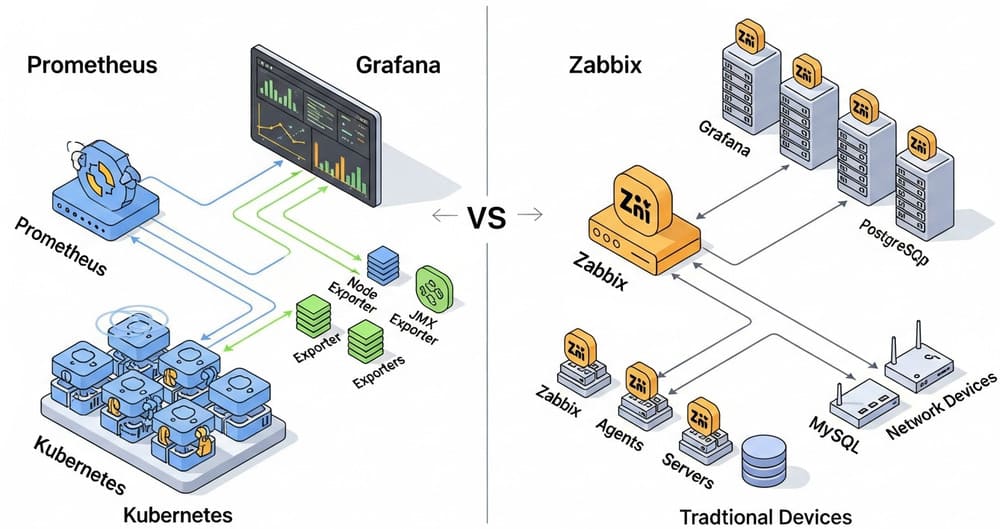
Prometheus vs Zabbix for Data Platforms
Alex
|
Nov 7, 2025
Data
VS
ClickHouse
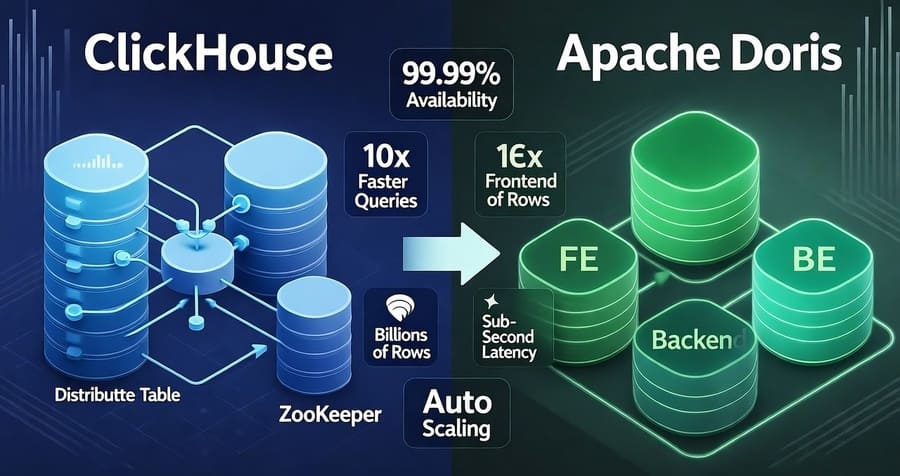
Apache Doris vs ClickHouse
Alex
|
Nov 6, 2025
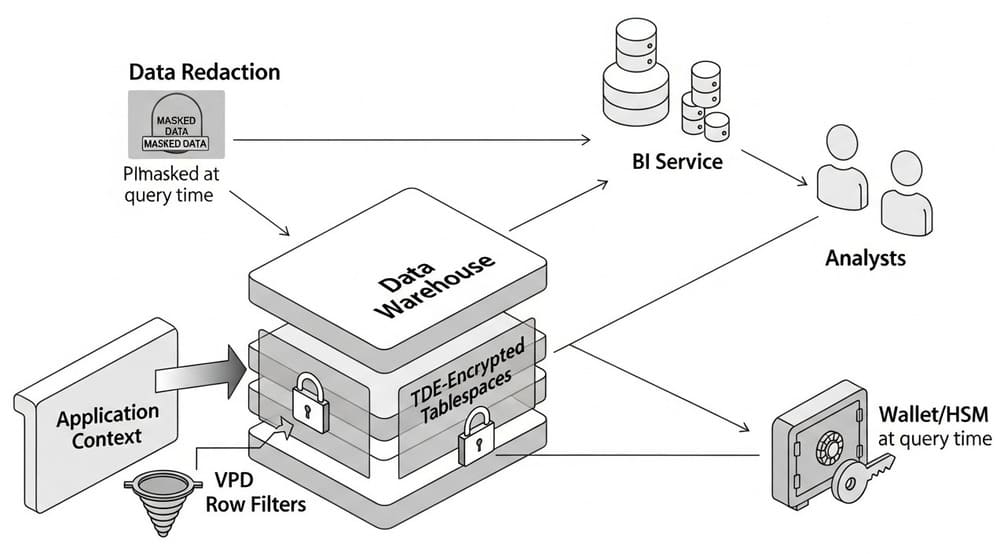
Oracle
Secure by Design on Oracle
Alex
|
Nov 4, 2025
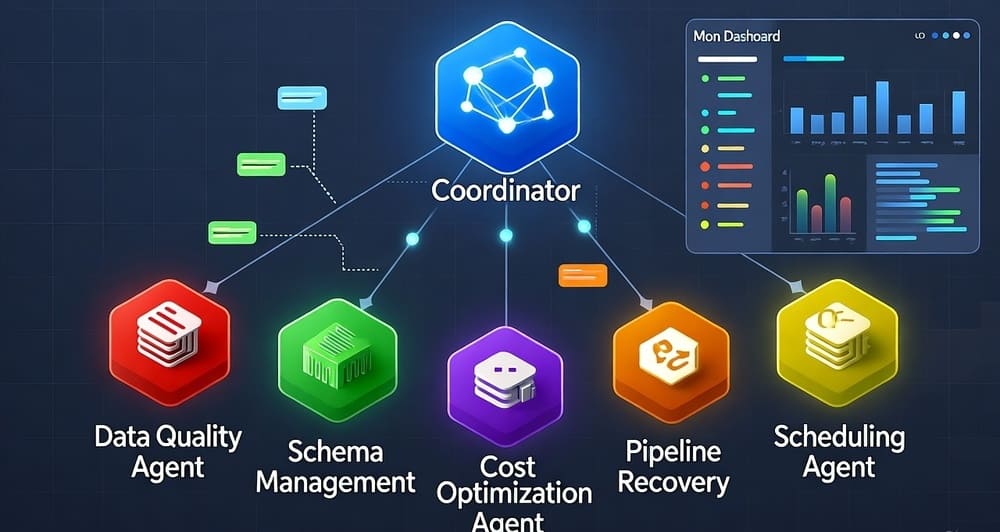
AI
DevOps
Multi-Agent Orchestration
Alex
|
Oct 29, 2025
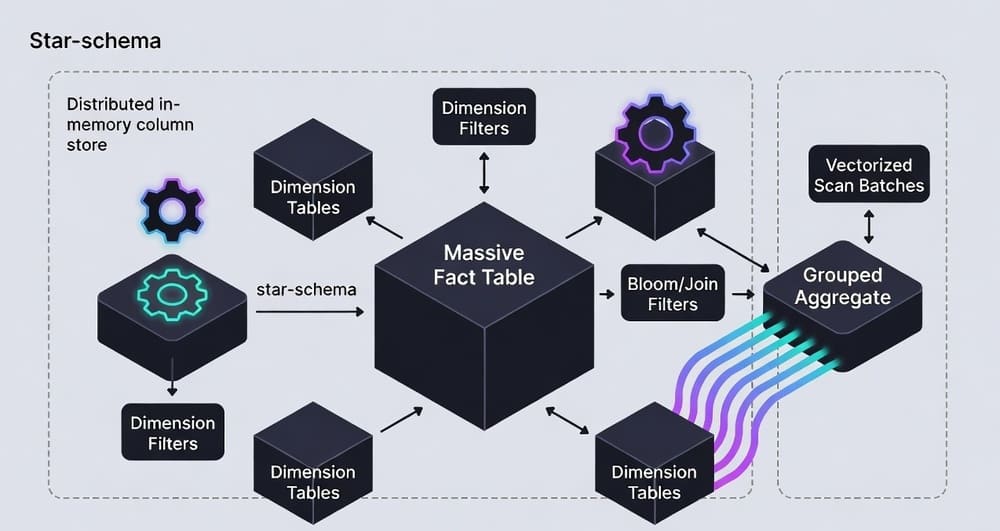
Oracle
In-Memory Column Stores for BI
Alex
|
Oct 28, 2025
1
2
…
17
Next »