
Agentic AI in Data Engineering: How AI Agents Are Automating the Entire Data Lifecycle
Introduction: The Dawn of Autonomous Data Engineering
Data engineering has long been the backbone of modern analytics and AI initiatives, yet it remains one of the most resource-intensive and repetitive disciplines in technology. Traditional data pipelines require constant human intervention—monitoring data quality, handling schema changes, optimizing performance, and troubleshooting failures. Even with modern orchestration tools like Airflow and dbt, data engineers spend countless hours on reactive maintenance rather than strategic innovation.
Enter Agentic AI—a paradigm shift that’s fundamentally changing how we approach data engineering. Unlike conventional AI assistants that simply respond to prompts, AI agents are autonomous entities capable of perceiving their environment, making decisions, and taking actions to achieve specific goals. In the data engineering context, these agents don’t just help you write SQL queries or debug pipelines; they proactively manage entire data workflows, anticipate issues before they occur, and continuously optimize systems without human intervention.
This article explores how Google’s Data Engineering Agent, Microsoft’s Agent Framework, and emerging platforms like Fresh Gravity’s Agentic Intelligent Data Engineering (AiDE) solutions are revolutionizing the data lifecycle. Whether you’re a data engineer drowning in pipeline maintenance, an ML engineer frustrated by data availability issues, or a platform architect planning your next-generation data infrastructure, understanding agentic AI is no longer optional—it’s essential.
What you’ll learn:
- The fundamental architecture of AI agents in data engineering
- Real-world applications across the entire data lifecycle
- Multi-agent collaboration patterns and context engineering techniques
- How major cloud providers are implementing agentic systems
- Governance, security, and practical implementation considerations
- The future trajectory of autonomous data platforms
Understanding Agentic AI: Beyond Traditional Automation
What Makes AI Agents Different?
Traditional automation in data engineering follows predefined rules and workflows. If condition X occurs, execute action Y. This deterministic approach works well for known scenarios but fails spectacularly when faced with novel situations or complex decision-making requirements.
Agentic AI systems, by contrast, exhibit four critical characteristics:
- Autonomy: Agents operate independently, making decisions without constant human oversight based on their understanding of goals and constraints.
- Reactivity: They perceive and respond to changes in their environment in real-time, whether that’s detecting data quality anomalies, schema drift, or performance degradations.
- Proactivity: Rather than merely reacting, agents anticipate future states and take preventive actions—scheduling optimizations during low-traffic periods or pre-scaling resources ahead of expected data spikes.
- Social Ability: Multiple agents collaborate, negotiate, and coordinate to accomplish complex objectives that no single agent could achieve alone.
In data engineering specifically, this translates to systems that can understand natural language requirements (“Create a pipeline that ingests customer events from Kafka, enriches them with demographic data, and maintains a slowly changing dimension in Snowflake”), design appropriate architectures, implement the solution, monitor its performance, and continuously optimize based on usage patterns—all with minimal human intervention.
The Agent Architecture Stack
Modern data engineering agents operate on a sophisticated technical stack:
Perception Layer: Integrates with data infrastructure to monitor pipeline health, data quality metrics, resource utilization, query performance, and user behavior patterns. This layer uses specialized connectors to various data platforms, observability tools, and orchestration systems.
Reasoning Engine: Powered by large language models (LLMs) fine-tuned on data engineering knowledge, this component analyzes perceived information, diagnoses issues, evaluates trade-offs, and formulates action plans. Advanced implementations use techniques like chain-of-thought reasoning and retrieval-augmented generation (RAG) to access relevant documentation and historical context.
Action Execution Layer: Translates decisions into concrete actions—generating and deploying code, modifying infrastructure configurations, triggering orchestration workflows, or escalating to human operators when necessary.
Memory Systems: Maintains both short-term context (current pipeline state, recent changes) and long-term knowledge (historical performance patterns, successful optimization strategies, failure modes) to inform better decisions over time.
The Data Lifecycle Reimagined: Agent Applications Across Every Stage
1. Autonomous Data Ingestion and Integration
Traditional data ingestion requires data engineers to manually configure connectors, handle authentication, manage API rate limits, and write custom transformation logic for each source system. Agentic AI fundamentally changes this model.
Google’s Data Engineering Agent demonstrates this capability through natural language pipeline creation. A platform architect can simply describe: “Connect to our Salesforce production instance, extract all account and opportunity data modified in the last 24 hours, and load it incrementally to BigQuery with proper deduplication.”
The agent then:
- Analyzes available Salesforce APIs and selects the optimal extraction method (Bulk API vs. REST API based on data volume)
- Configures authentication using credentials from secret management systems
- Designs an incremental load strategy using watermark columns
- Implements idempotent logic to handle duplicate data
- Sets up monitoring for API quota consumption and extraction failures
- Documents the entire pipeline with generated diagrams and runbooks
What’s particularly revolutionary is the agent’s ability to handle source system changes autonomously. When Salesforce adds new fields or deprecates APIs, the agent detects these changes, evaluates their impact on downstream consumers, and either adapts the pipeline automatically or alerts engineers with specific recommendations.
Multi-source orchestration becomes dramatically simpler with agent collaboration. Instead of a single monolithic orchestrator, specialized agents coordinate ingestion from different source systems—a Salesforce agent, an API agent for third-party services, a database agent for transactional systems—each optimizing their domain while maintaining consistency through shared state management.
2. Intelligent Data Transformation and Modeling
Data transformation has traditionally been the domain of tools like dbt, Spark, and SQL-based ETL frameworks. While these tools are powerful, they still require significant human expertise to design dimensional models, optimize query performance, and maintain transformation logic.
Agentic transformation systems elevate this to a new level by understanding business context alongside technical requirements. When tasked with “Create a customer 360 view that integrates behavioral, transactional, and support interaction data,” the agent:
- Discovers relationships between disparate datasets by analyzing schema metadata, foreign key relationships, and semantic similarities in column names and data distributions
- Designs optimal join strategies considering data volumes, cardinality, and query patterns
- Generates transformation logic that handles data quality issues (missing values, duplicates, conflicting records) based on learned best practices
- Implements slowly changing dimensions with appropriate Type 1/2/3 logic based on the business significance of historical changes
- Creates data quality tests that validate business rules, referential integrity, and statistical properties
The Fresh Gravity AiDE platform exemplifies this approach with agents that continuously refine transformations based on downstream usage. If analysts frequently filter or aggregate data in specific ways, the agent proactively materializes those patterns as pre-computed views, dramatically improving query performance without manual intervention.
Context engineering is crucial here. Effective transformation agents require deep understanding of:
- Business domain semantics (what “customer lifetime value” means for your organization)
- Data lineage and dependencies
- Performance characteristics of target platforms
- Existing coding standards and naming conventions
This context is provided through structured knowledge bases, historical transformation patterns, and ongoing feedback loops with data consumers.
3. Proactive Data Quality and Observability
Data quality has historically been reactive—engineers discover issues after they’ve impacted downstream analytics or ML models. Agentic AI enables a fundamentally proactive approach.
Autonomous data quality agents operate continuously, learning normal data patterns and detecting anomalies before they cascade through pipelines. These agents:
- Profile data automatically across thousands of attributes, establishing statistical baselines for distributions, cardinalities, null rates, and inter-column correlations
- Detect semantic anomalies that traditional rule-based systems miss, like valid-but-suspicious patterns (e.g., all transactions suddenly occurring at midnight) using LLM reasoning
- Predict data quality issues by analyzing leading indicators—if upstream API response times increase, the agent anticipates potential timeout failures and preemptively adjusts retry logic
- Auto-remediate common issues such as applying learned transformation rules to fix format inconsistencies or invoking data repair workflows
- Prioritize alerts intelligently by assessing downstream impact, distinguishing critical revenue-affecting issues from cosmetic inconsistencies
Microsoft’s Agent Framework enables sophisticated multi-agent quality scenarios where specialist agents focus on different quality dimensions:
- A completeness agent monitors for missing or delayed data arrivals
- A consistency agent validates referential integrity across datasets
- A timeliness agent ensures SLA compliance for data freshness
- An accuracy agent performs statistical validation against known ground truth
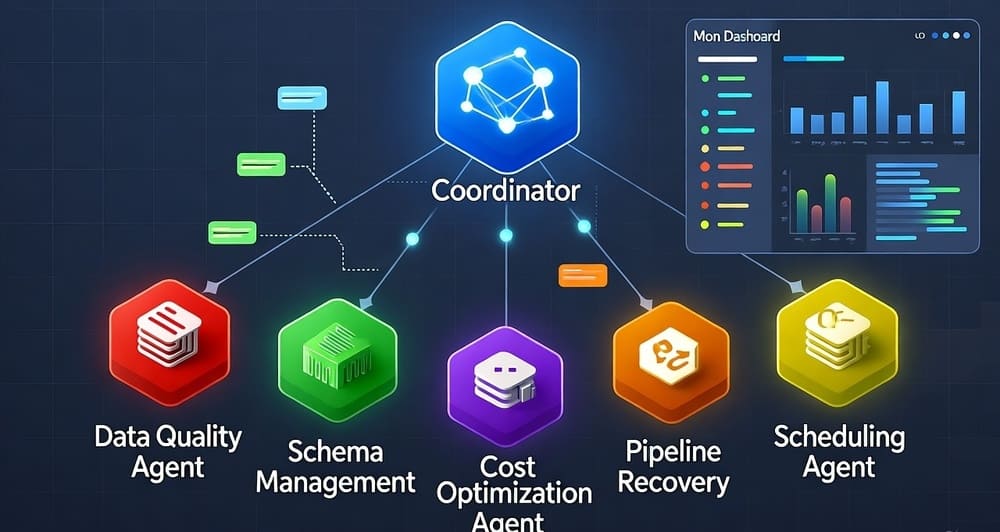
These agents collaborate through a coordinator that synthesizes their findings into coherent quality reports and orchestrates remediation workflows.
4. Autonomous Performance Optimization
Performance optimization traditionally requires deep expertise in query planning, indexing strategies, partitioning schemes, and platform-specific tuning parameters. Agentic systems democratize this expertise.
Optimization agents continuously analyze query patterns, resource utilization, and performance metrics to identify improvement opportunities:
- Automatic materialization decisions: When agents detect frequently repeated expensive joins or aggregations, they create materialized views or pre-aggregated tables, then monitor their usage to ensure ROI justifies storage costs
- Intelligent partitioning and clustering: Analyzing query predicates to determine optimal partitioning schemes for data lakes and warehouses, then executing reorganization during low-usage windows
- Dynamic resource allocation: Scaling compute resources based on predicted workload patterns rather than reactive thresholds, informed by historical trends and business calendars
- Query rewriting: Automatically refactoring suboptimal SQL patterns into more efficient equivalents while preserving semantic correctness
Google Cloud’s Data Engineering Agent integrates deeply with BigQuery’s execution engine, accessing query plans and slot usage statistics to make informed optimization decisions. When it identifies a frequently-scanned large table, it might recommend and implement column-level clustering, estimate the cost-benefit tradeoff, and automatically validate that query performance improves post-optimization.
5. Adaptive Pipeline Orchestration
Traditional orchestration tools like Airflow excel at executing predefined DAGs, but adapting to changing conditions requires manual intervention. Agentic orchestrators introduce dynamic, self-optimizing workflows.
Intelligent orchestration agents go beyond static task dependencies:
- Dynamic parallelization: Analyzing data volumes and resource availability to determine optimal parallelism levels for each pipeline run
- Adaptive scheduling: Learning execution time patterns to schedule pipelines for completion just-in-time for downstream consumers, minimizing data latency without wasting compute
- Smart retries: Understanding failure patterns to apply contextual retry strategies—immediate retries for transient network issues, exponential backoff for rate-limited APIs, circuit-breaking for persistent upstream failures
- Cross-pipeline optimization: Coordinating multiple pipelines to share intermediate results, reorder execution for resource efficiency, or merge redundant operations
The key innovation is intent-based orchestration. Rather than specifying exact task sequences, engineers define outcomes (“Ensure customer analytics data is refreshed daily by 8 AM ET with less than 0.1% error rate”), and agents determine the optimal execution strategy considering current system state, resource availability, and risk tolerance.
Multi-Agent Collaboration: Orchestrating Specialized Agents
The most powerful agentic systems don’t rely on a single superintelligent agent but rather orchestrate specialized agents that excel in narrow domains while collaborating to achieve complex objectives.
Collaboration Patterns in Data Engineering
Hierarchical Coordination: A master planning agent decomposes high-level objectives into subtasks, delegating to specialist agents (ingestion, transformation, quality, optimization) and synthesizing their results. This mirrors how engineering teams organize with tech leads coordinating specialist contributors.
Peer-to-Peer Negotiation: Autonomous agents negotiate resource allocation and priority. For example, an ingestion agent needing to reload historical data negotiates with an analytics agent about acceptable downtime windows, finding mutually agreeable solutions without human mediation.
Blackboard Systems: Agents communicate through shared knowledge repositories. When a quality agent detects a schema change, it posts this information to a shared context space. Transformation agents monitoring this space proactively adapt their logic, while documentation agents update schema registries automatically.
Marketplace Models: Emerging platforms create agent marketplaces where specialized agents (a Snowflake optimization agent, a Databricks Delta Lake agent, a dbt modeling agent) are discovered and composed into custom solutions, similar to microservices architectures but with intelligent autonomous components.
Context Engineering: Teaching Agents Your Environment
The effectiveness of agentic systems depends heavily on context engineering—providing agents with rich, structured knowledge about your specific data environment.
Critical context includes:
Organizational Knowledge: Business glossaries, metric definitions, data ownership mappings, compliance requirements, and approved technology stacks. This prevents agents from making technically correct but organizationally inappropriate decisions.
Historical Intelligence: Past incidents and their resolutions, successful optimization strategies, failed experiments, and lessons learned. This institutional knowledge prevents agents from repeating mistakes.
Environmental Constraints: Budget limits, SLA requirements, security boundaries, regulatory restrictions, and technical dependencies. Agents must understand not just what’s technically possible but what’s organizationally permissible.
Feedback Loops: Structured mechanisms for humans to correct agent decisions, with those corrections becoming training data that improves future agent behavior.
Microsoft’s Agent Framework emphasizes retrieval-augmented generation (RAG) architectures where agents query knowledge bases containing documentation, runbooks, and past conversations to inform decision-making. This grounds agent reasoning in organizational reality rather than generic best practices that may not apply to your specific context.
Real-World Implementation: From Pilot to Production
Starting Your Agentic AI Journey
Organizations successfully adopting agentic data engineering typically follow a phased approach:
Phase 1: Augmentation (Months 1-3) Start with agents as intelligent assistants rather than autonomous operators. Deploy agents that generate code, suggest optimizations, or draft documentation—but with human review and approval before execution. This builds trust and allows your team to learn the agents’ capabilities and limitations.
Focus areas:
- Natural language-to-SQL generation for ad-hoc analytics
- Automated data profiling and quality report generation
- Pipeline code generation with human validation
Phase 2: Supervised Autonomy (Months 4-9) Grant agents authority to execute routine operations within guardrails. Agents handle known scenarios autonomously while escalating novel or high-risk situations to humans.
Appropriate use cases:
- Automatic schema evolution handling for non-critical tables
- Performance optimization during maintenance windows
- Data quality remediation for predefined issue types
Phase 3: Full Autonomy (Months 10+) Allow agents to manage entire subsystems independently, with human oversight through dashboards and alerts rather than approval workflows.
Mature implementations:
- End-to-end pipeline lifecycle management
- Multi-agent collaborative optimization
- Autonomous incident response with human escalation only for complex scenarios
Governance and Safety Considerations
Autonomous agents operating on production data systems require robust governance frameworks:
Permission Management: Implement fine-grained role-based access control (RBAC) for agents, limiting their permissions to specific resources and operations. An ingestion agent shouldn’t have deletion rights on production tables.
Audit Trails: Every agent action must be logged with full context—what decision was made, why, what alternatives were considered, and what outcomes resulted. This is critical for regulatory compliance and debugging.
Safety Constraints: Define hard boundaries agents cannot cross—maximum query costs, data deletion restrictions, production deployment gates. These act as circuit breakers preventing catastrophic errors.
Human-in-the-Loop: Critical operations should require human approval, even for mature agent deployments. Define clear escalation policies for edge cases, high-impact changes, or situations where agent confidence is low.
Explainability: Agents must articulate their reasoning in human-understandable terms. When an agent suggests rewriting a query, it should explain the performance bottleneck it identified and why the proposed alternative is superior.
Integration with Existing Data Stacks
Agentic systems don’t require wholesale replacement of your current infrastructure. They integrate with existing tools:
Orchestration Layer: Agents can trigger and monitor Airflow/Prefect workflows, dynamically generating DAGs or modifying schedules based on learned patterns.
Transformation Frameworks: Rather than replacing dbt, agents generate dbt models, write tests, and optimize materializations while respecting your dbt project structure and coding standards.
Data Platforms: Agents interact with Snowflake, BigQuery, Databricks, Redshift through standard APIs and SQL interfaces, making them largely platform-agnostic.
Observability Stack: Agents consume metrics from DataDog, Monte Carlo, or custom monitoring solutions to inform decisions, while also emitting their own telemetry for meta-monitoring.
The key architectural principle is loose coupling—agents should enhance rather than replace proven data engineering tools, providing an intelligent orchestration layer that coordinates and optimizes existing systems.
The Competitive Landscape: Major Players and Emerging Solutions
Google Cloud’s Data Engineering Agent
Google’s approach focuses on natural language-driven pipeline automation integrated deeply with BigQuery and Dataflow. The Data Engineering Agent excels at translating business requirements into technical implementations, leveraging Google’s foundation models fine-tuned on vast amounts of data engineering patterns.
Key differentiators:
- Native BigQuery integration for query optimization and cost management
- Multimodal understanding allowing agents to interpret diagrams and ERDs
- Strong emphasis on explainability with detailed reasoning chains
- Enterprise-grade security leveraging Google Cloud’s IAM and VPC controls
Microsoft’s Agent Framework
Microsoft’s strategy emphasizes flexibility and composability, providing a framework for building custom agent solutions rather than a monolithic product. This appeals to organizations with complex, heterogeneous data estates.
Notable capabilities:
- Agent orchestration through Azure AI Studio
- Deep integration with Microsoft Fabric for unified analytics
- Support for multi-agent collaboration patterns
- Emphasis on responsible AI with built-in content filtering and safety mechanisms
Fresh Gravity’s AiDE Platform
Fresh Gravity represents the emerging category of specialized AiDE (Agentic Intelligent Data Engineering) solutions focused exclusively on autonomous data operations. These platforms often provide:
- Pre-built agents optimized for common data engineering patterns
- Lower-code deployment compared to building custom agents from scratch
- Focus on rapid ROI through automation of repetitive tasks
- Startup agility in adopting latest LLM and agent architecture innovations
Open Source and Community Solutions
The open-source ecosystem is rapidly developing agentic capabilities:
- LangChain/LangGraph: Popular frameworks for building agent systems with strong data integration capabilities
- AutoGen: Microsoft Research’s framework for multi-agent conversations
- CrewAI: Specialized in orchestrating role-based AI agent teams
These tools provide building blocks for organizations wanting to develop custom agentic solutions while maintaining full control over intellectual property and data residency.
Challenges and Limitations: The Realities of Agentic AI
Despite tremendous promise, agentic AI in data engineering faces real challenges:
Technical Limitations
Reasoning Boundaries: Current LLMs excel at pattern matching and code generation but struggle with complex multi-step reasoning involving deep system understanding. Agents may propose syntactically correct but semantically flawed solutions.
Context Window Constraints: Even large context windows (100K+ tokens) can’t capture the full complexity of enterprise data environments. Agents may miss critical dependencies or constraints not explicitly provided in their context.
Hallucination Risks: LLMs can confidently generate incorrect information. In data engineering, this might manifest as suggesting nonexistent API endpoints, incompatible configuration options, or optimization techniques that don’t apply to your platform version.
Cost at Scale: Running sophisticated agents continuously across large data estates can incur significant LLM API costs. Organizations must balance agent intelligence against operational expenses.
Organizational Challenges
Trust Gap: Data engineers often resist ceding control to autonomous systems, particularly for production-critical pipelines. Building trust requires demonstrating consistent reliability over time.
Skills Evolution: As agents handle routine tasks, data engineers must evolve from implementation-focused to architecture and strategy-focused roles. This transition requires organizational change management.
Accountability: When an agent makes a mistake, determining responsibility becomes complex. Organizations need clear accountability frameworks distinguishing agent errors from human oversight failures.
Knowledge Capture: Agents’ effectiveness depends on comprehensive organizational knowledge. Companies often struggle to codify tribal knowledge and undocumented practices into machine-readable formats.
Practical Mitigation Strategies
- Start narrow: Deploy agents in low-risk environments (development, sandboxes) before production
- Implement strong guardrails: Use multiple validation layers and require high confidence thresholds for autonomous actions
- Maintain human oversight: Design systems where humans review agent decisions rather than blindly trusting outputs
- Invest in observability: Instrument agents comprehensively to understand their decision-making processes
- Build gradually: Increase agent autonomy incrementally as trust and understanding grow
The Future: Towards Fully Autonomous Data Platforms
Emerging Trends and Capabilities
The next evolution of agentic data engineering will likely include:
Self-Healing Data Ecosystems: Platforms that automatically detect, diagnose, and remediate issues across the entire data stack without human intervention, from infrastructure failures to data quality degradations.
Predictive Data Operations: Agents that don’t just react to current conditions but predict future states—anticipating pipeline failures before they occur, forecasting data growth to prevent storage exhaustion, or predicting when data freshness SLAs might be breached.
Semantic Understanding: Advanced agents that truly understand business semantics, not just technical patterns. These agents could participate in data governance discussions, suggest new metrics aligned with business strategy, or identify opportunities for data monetization.
Cross-Organizational Collaboration: In the longer term, agents from different organizations might negotiate data sharing agreements, establish interoperability standards, and coordinate joint analytics—all while respecting privacy and security boundaries.
Augmented Data Teams: Rather than replacing data engineers, the future envisions tight human-agent collaboration where each focuses on their strengths. Engineers provide strategic direction, domain expertise, and creative problem-solving, while agents handle execution, optimization, and continuous monitoring.
Preparing Your Organization
To position your data organization for the agentic future:
- Build a strong data foundation: Agents amplify existing capabilities but can’t compensate for fundamentally poor data quality, inconsistent governance, or technical debt. Invest in data observability, cataloging, and quality frameworks.
- Develop context repositories: Start documenting organizational knowledge, business logic, and constraints in structured formats that agents can consume. This includes data dictionaries, runbooks, architecture decision records, and coding standards.
- Experiment actively: Set up sandboxes for agent experimentation. Allow your team to explore capabilities, understand limitations, and develop best practices before production deployment.
- Invest in agent literacy: Train your data team on prompt engineering, agent architecture, and effective human-agent collaboration. This is becoming as fundamental as SQL proficiency.
- Establish governance early: Define policies for agent permissions, audit requirements, and escalation procedures before widespread deployment. It’s much harder to impose governance retroactively.
- Think architecturally: Design data systems with agent interaction in mind—well-documented APIs, comprehensive telemetry, clear separation of concerns, and event-driven architectures that agents can easily integrate with.
Key Takeaways
Agentic AI represents a fundamental shift in data engineering—from humans writing explicit code for every operation to defining high-level objectives that AI agents autonomously achieve through continuous perception, reasoning, and action.
Multi-agent collaboration unlocks capabilities impossible with monolithic systems—specialized agents working together handle complexity that no single agent or human could manage, while maintaining explainability through structured communication.
Success requires more than technology—effective agentic implementations demand organizational readiness, comprehensive context engineering, robust governance frameworks, and phased adoption strategies that build trust incrementally.
Major cloud providers are committing heavily—Google’s Data Engineering Agent and Microsoft’s Agent Framework signal that agentic capabilities will become standard features of enterprise data platforms, not exotic experiments.
The data engineer role is evolving, not disappearing—as agents handle routine implementation and optimization, data engineers elevate to strategic architects, domain experts, and agent coordinators who focus on problems requiring creativity, business judgment, and ethical reasoning.
Start experimenting now—the gap between organizations that master agentic data engineering and those that don’t will widen rapidly. Early adopters gain experience, develop best practices, and establish competitive advantages while the technology is still maturing.
The transition to agentic data platforms won’t happen overnight, but the trajectory is clear. Organizations that begin this journey now—thoughtfully, incrementally, with appropriate governance—will find themselves far better positioned to deliver the data agility, quality, and cost-efficiency that modern businesses demand.
Further Resources
Official Documentation:
- Google Cloud Data Engineering Agent documentation: cloud.google.com/data-engineering-agent
- Microsoft Agent Framework: learn.microsoft.com/azure/ai-services/agents
- LangChain Agent Documentation: python.langchain.com/docs/modules/agents
Industry Analysis:
- Gartner: “How Agentic AI Will Transform Data Management” (Subscription required)
- Forrester: “The Rise of Autonomous Data Operations”
Open Source Tools:
- LangGraph for agent orchestration: github.com/langchain-ai/langgraph
- AutoGen for multi-agent systems: github.com/microsoft/autogen
- CrewAI agent framework: github.com/joaomdmoura/crewai
Community & Discussion:
- AI Agents in Data Engineering LinkedIn Group
- r/dataengineering subreddit discussions on agentic AI
- Data Engineering Podcast episodes on autonomous systems











Leave a Reply